Q1
bdcopy1等值查询
bdcopy2等值查询
bdcopy1范围查询
bdcopy2范围查询
- 有b+树索引比没有索引的等值查询要快很多
B+树能够通过二分查找快速定位到目标值,避免扫描全表 - 有b+树索引比没有索引的范围查询要快一点
可能数据按插入顺序物理存储。如果是全表扫描,将顺序读取数据文件,I/O效率高。如果是索引扫描,将通过索引定位到离散的数据页,产生随机I/O。
Q2
bdcopy1
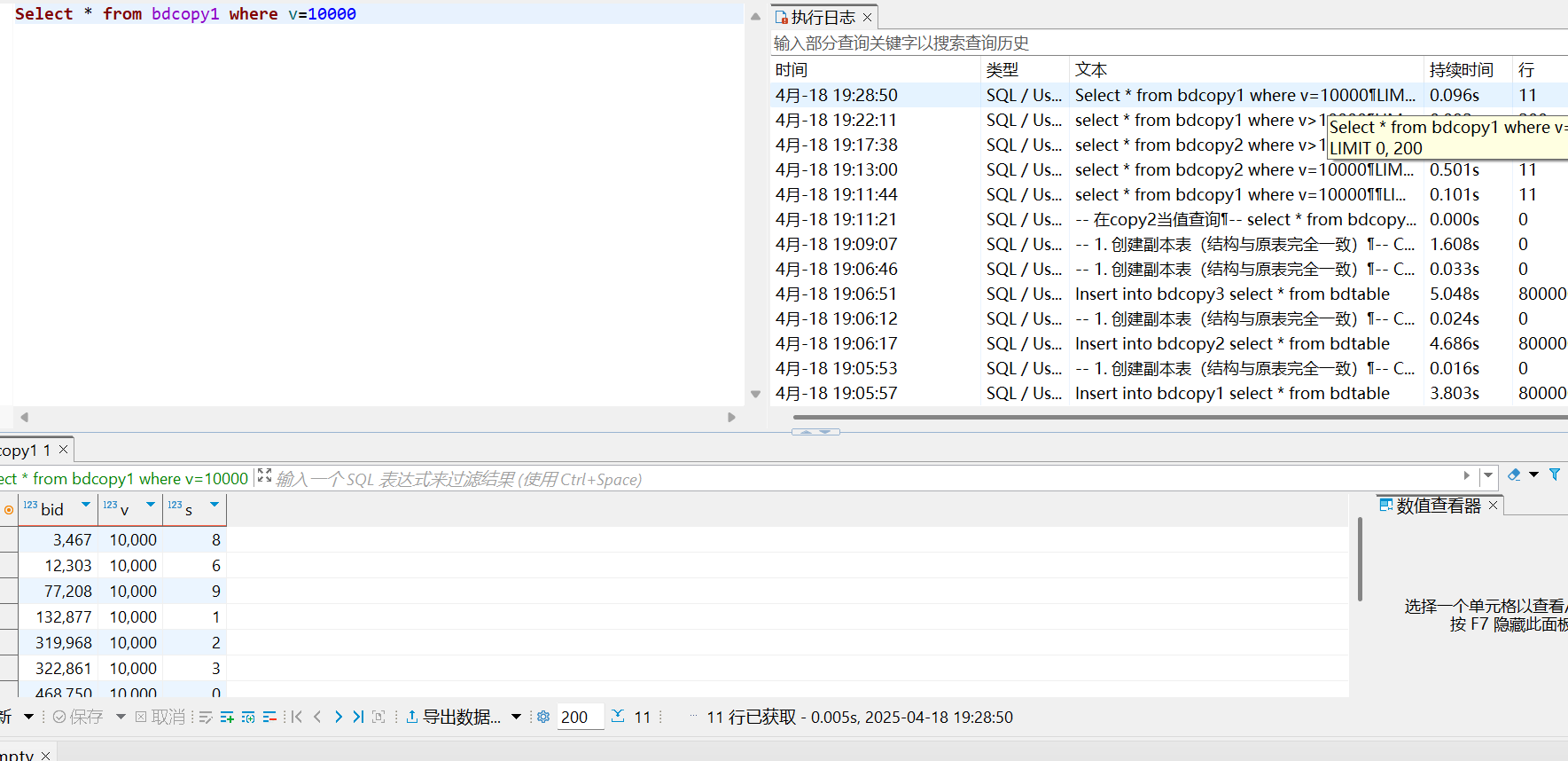
bdcopy3
二者速度几乎完全一样
bdcopy3也是b+树
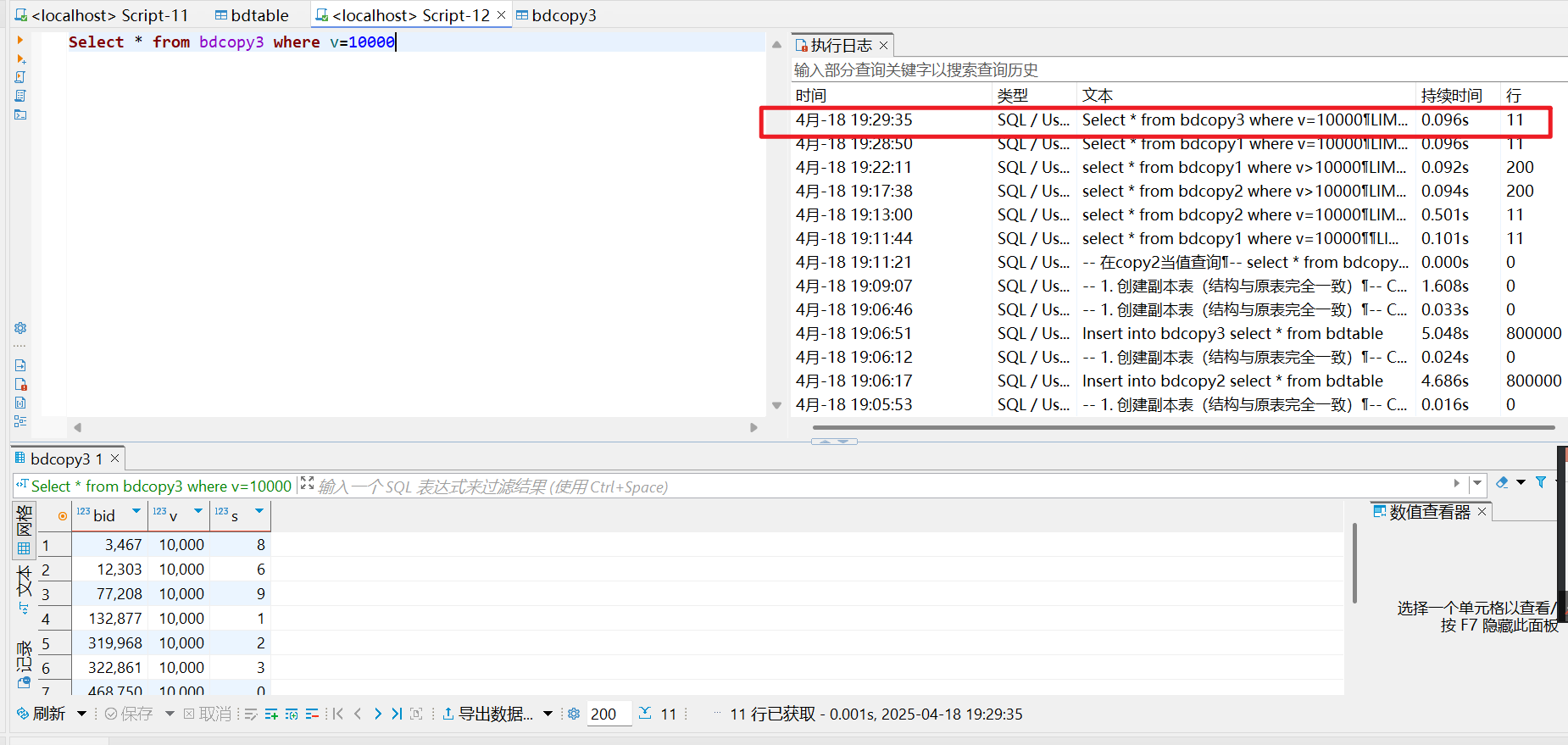
bdcopy4等值查询
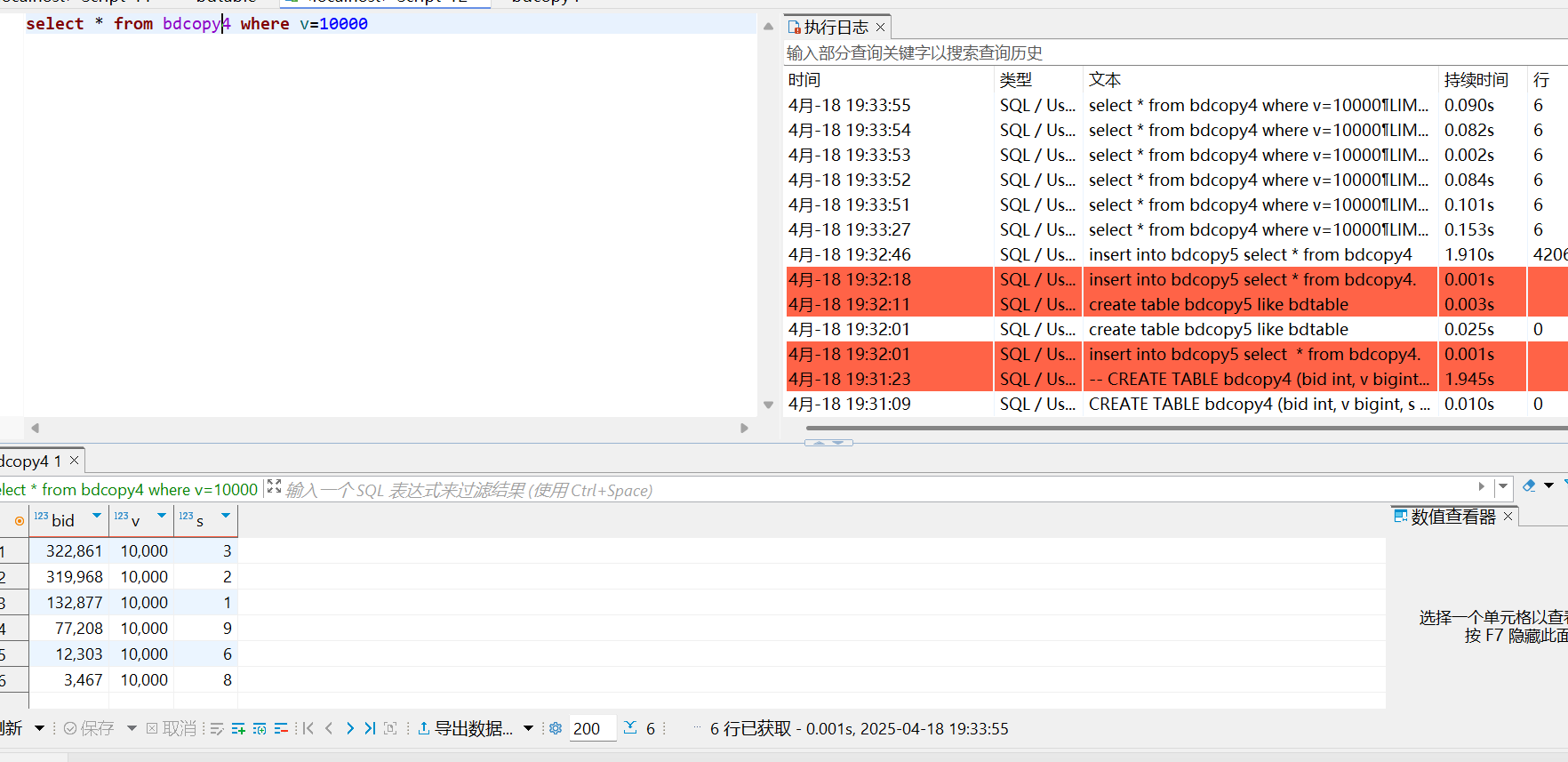
bdcopy5等值查询
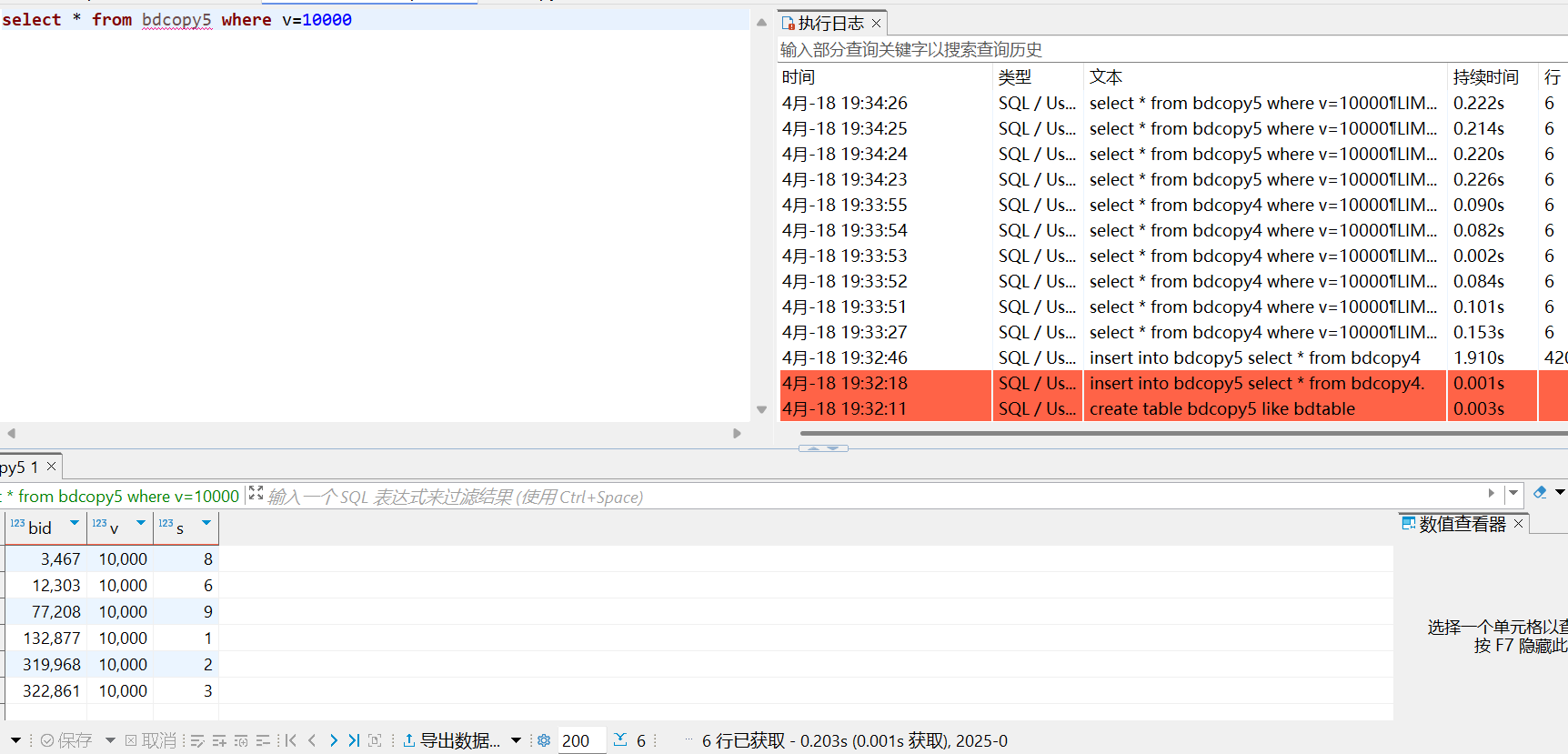
显然bdcopy4要比bdcopy5快很多,但意料之外的比b+树要慢
- hash比无索引快:通过hash函数直接映射,比顺序搜索要更快
- b+树比hash快:或许是因为哈希冲突过多导致链表遍历速度太慢(?)
Q3
bdcopy1
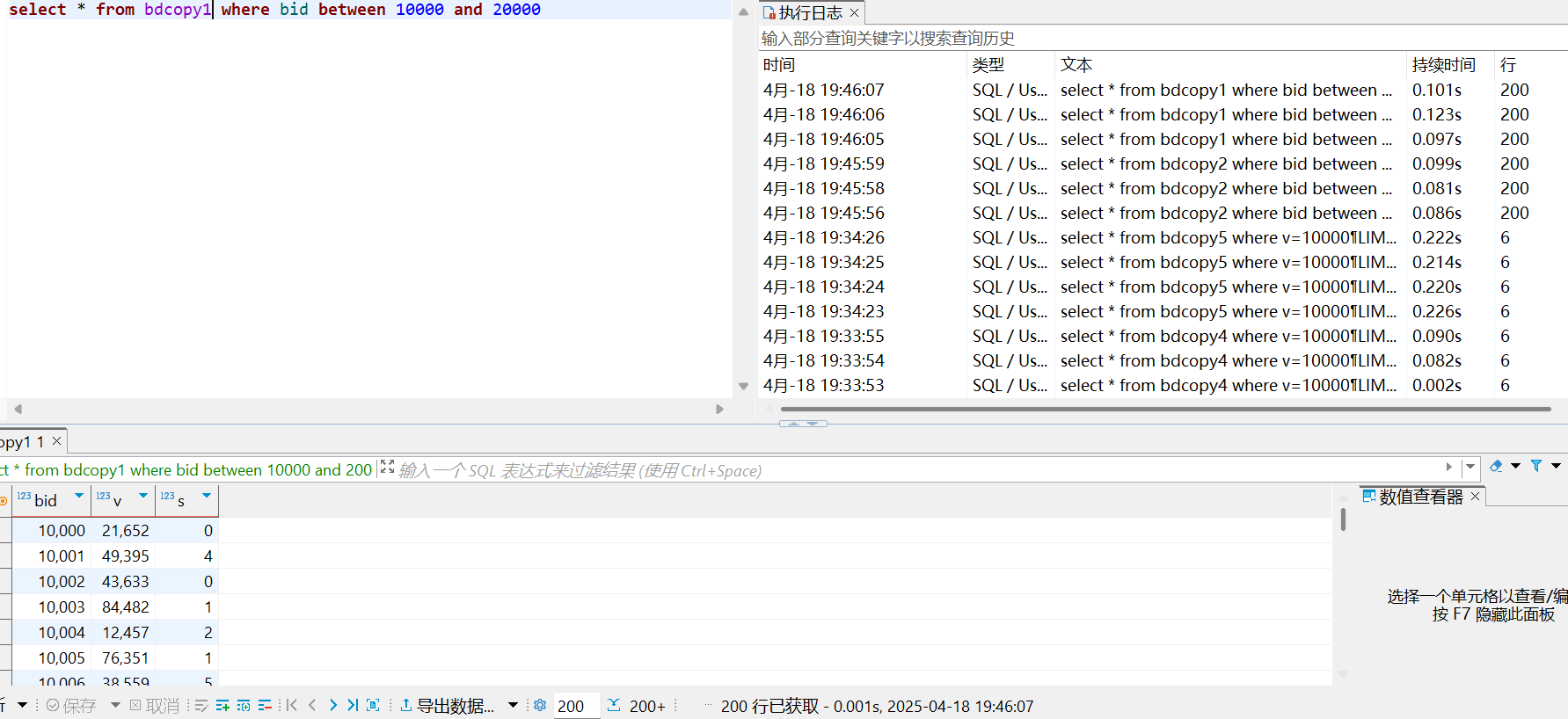
bdcopy2
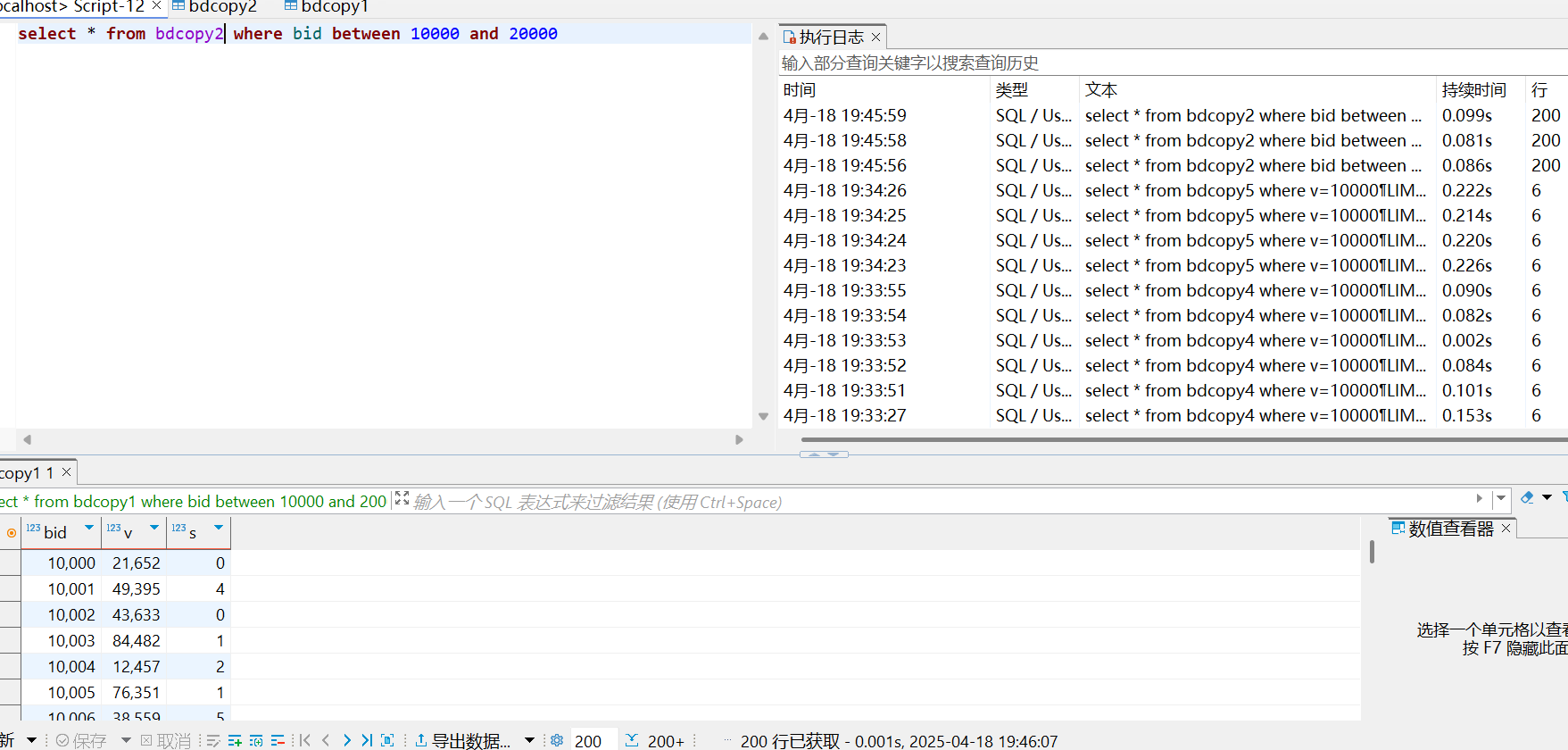
bdcopy2略快于bdcopy1
因为bdcopy2按主键bid的物理顺序连续存储。范围查询时,数据库可以高效顺序IO连续读取数据页。
而bdcopy1使用b+树索引,涉及到随机IO,效率极低
Q4
where v=17113 and s=10
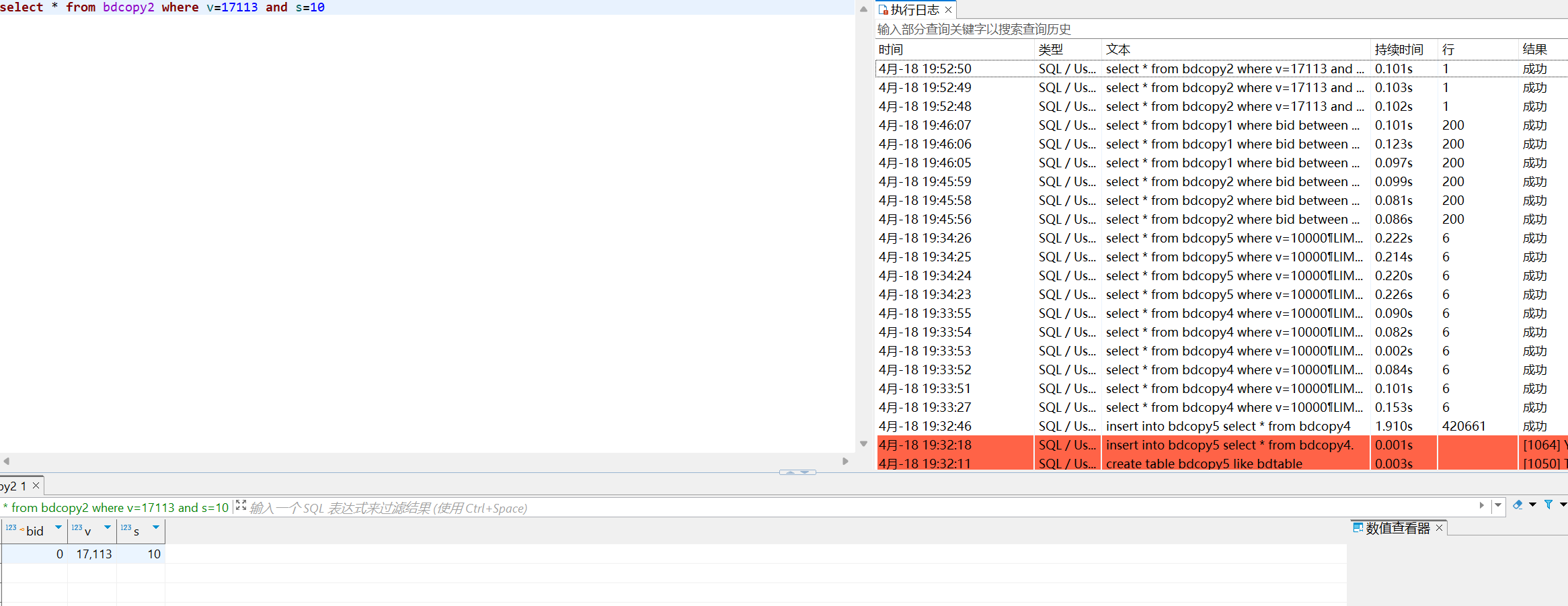
where v=17113
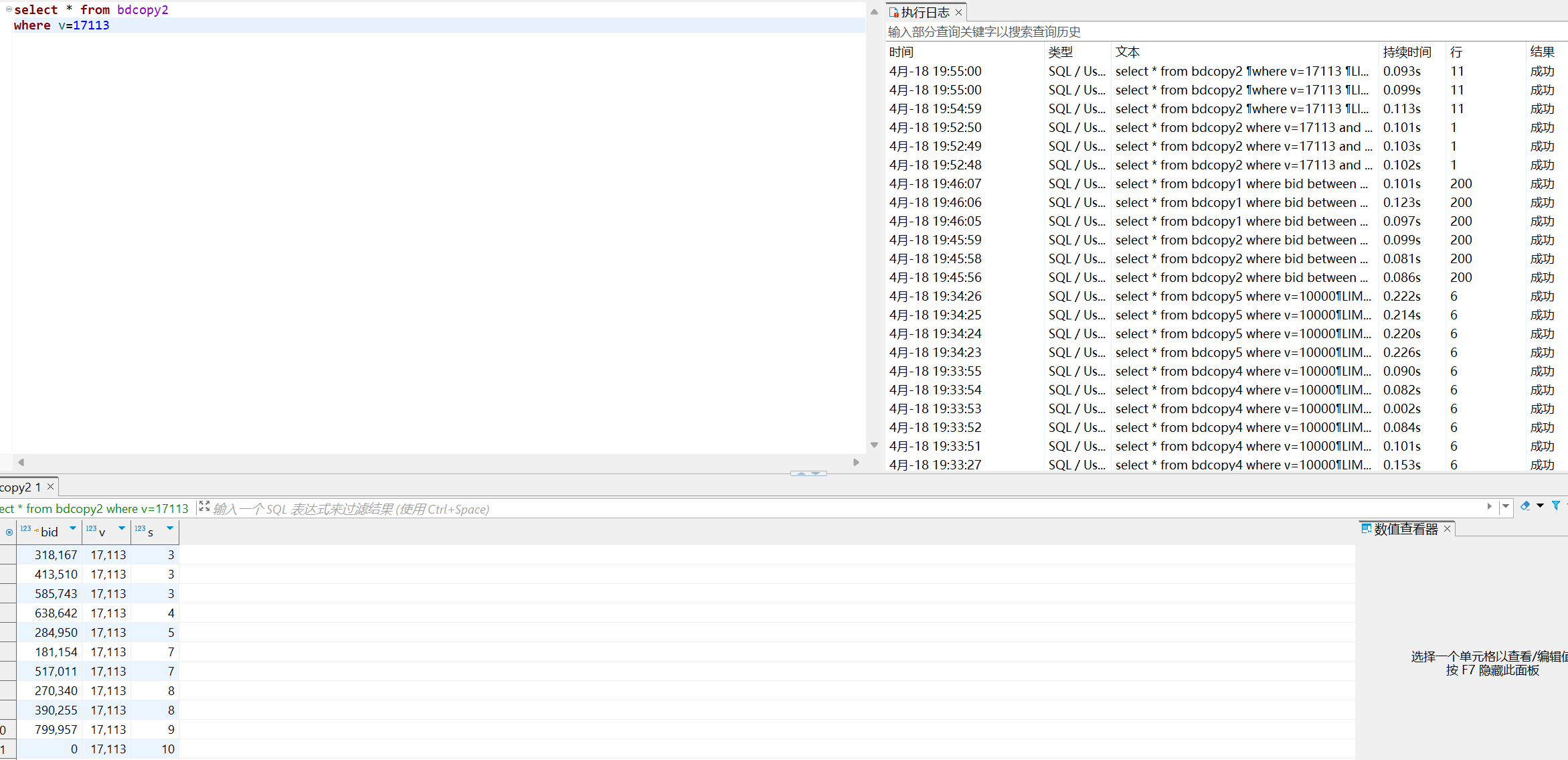
where s=10
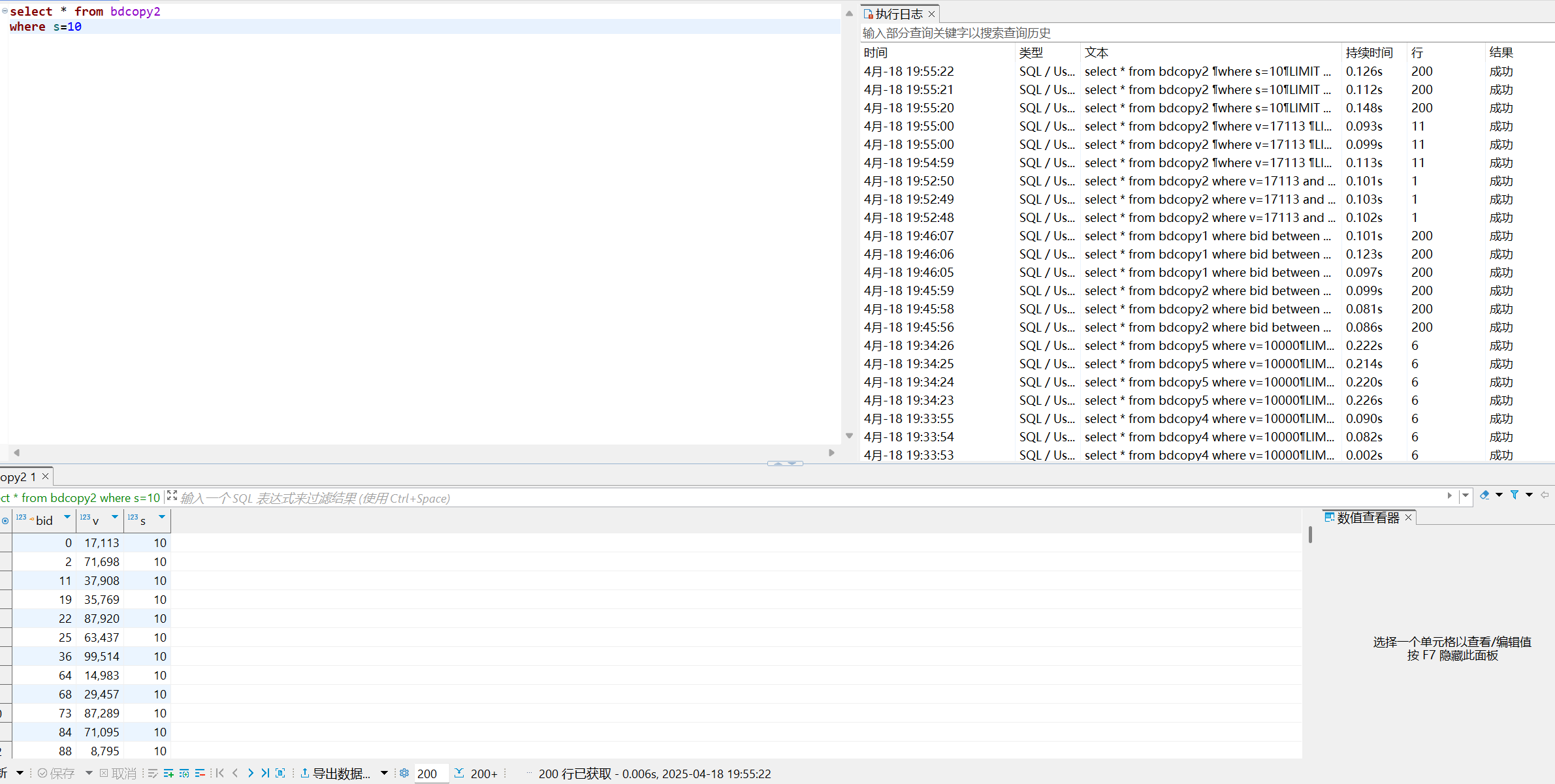
- 速度:where v=17113 and s=10 ≈ where v=17113 > where s=10
- where v=17113 and s=10
这个查询使用了联合索引中的两个字段。数据库可以快速定位到v=353535的行,然后在这些行中进一步筛选出s=3的行。因为使用了联合索引,这个查询的速度通常是最快的。 - where v=17113
这个查询只使用了联合索引中的v字段。数据库仍然可以利用联合索引来快速定位到v=353535的行,但是它不需要考虑s字段的值。虽然检查行数更多,但可能是因为无需考虑s值,所以效率与where v=17113 and s=10大致相同 - where s=10
这个查询只使用了联合索引中的s字段。数据库无法直接使用联合索引来快速定位到s=3的行,需要执行全表扫描,检查每一行来找到s=3的行。因此速度是最慢的
// Explain select * from bdcopy2 where v>10000 and s=10
/* select#1 */ select `lab4-2`.`bdcopy2`.`bid` AS `bid`,`lab4-2`.`bdcopy2`.`v` AS `v`,`lab4-2`.`bdcopy2`.`s` AS `s` from `lab4-2`.`bdcopy2` where ((`lab4-2`.`bdcopy2`.`s` = 10) and (`lab4-2`.`bdcopy2`.`v` > 10000))
Q5
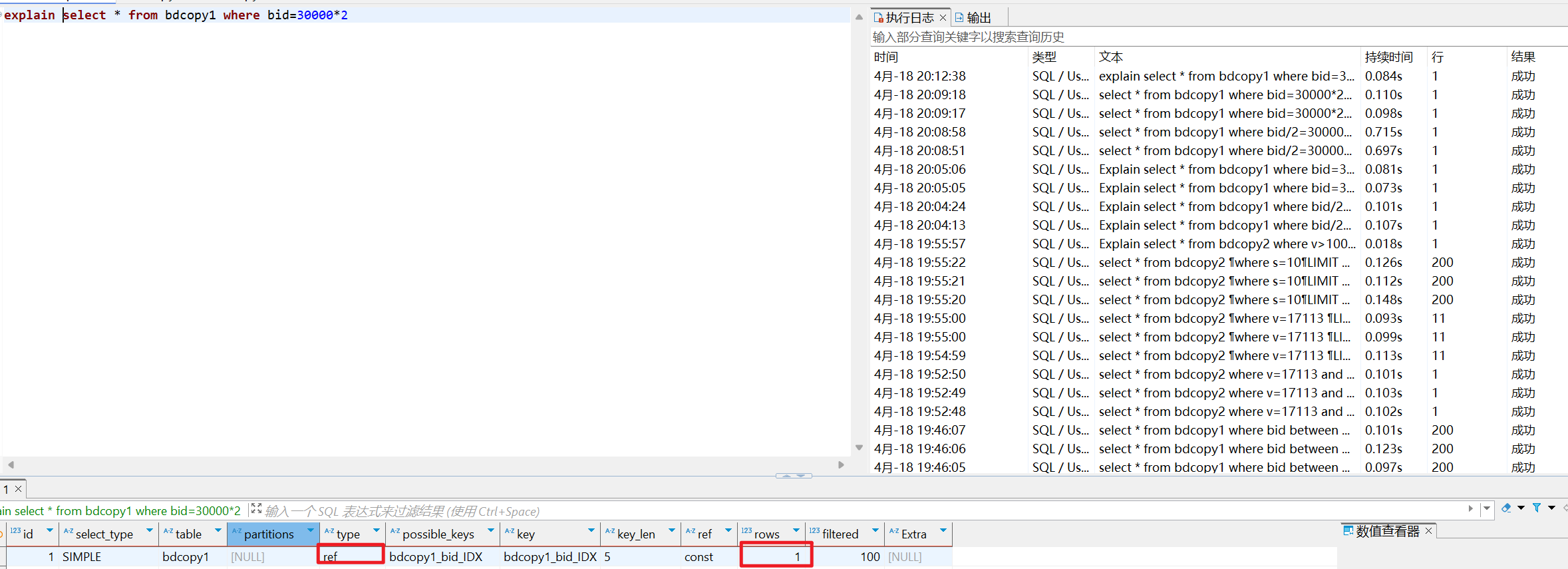
Explain select * from bdcopy1 where bid=30000*2
/* select#1 */ select `lab4-2`.`bdcopy1`.`bid` AS `bid`,`lab4-2`.`bdcopy1`.`v` AS `v`,`lab4-2`.`bdcopy1`.`s` AS `s` from `lab4-2`.`bdcopy1` where (`lab4-2`.`bdcopy1`.`bid` = (30000 * 2))
Explain select * from bdcopy1 where bid/2=30000
/* select#1 */ select `lab4-2`.`bdcopy1`.`bid` AS `bid`,`lab4-2`.`bdcopy1`.`v` AS `v`,`lab4-2`.`bdcopy1`.`s` AS `s` from `lab4-2`.`bdcopy1` where ((`lab4-2`.`bdcopy1`.`bid` / 2) = 30000)
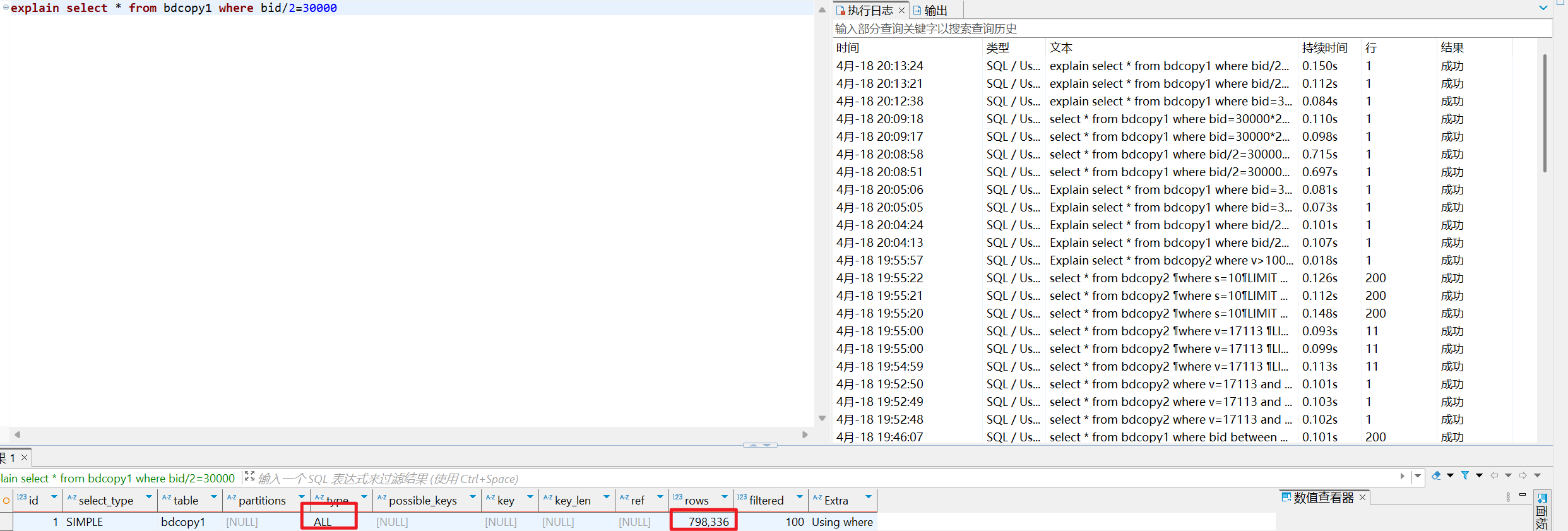
第一个的速度远快于第二个的速度,因为bid = 30000*2可以直接使用b+树索引二分查找定位,但bid/2 = 30000需要先全局遍历每行,再比较bid/2,无法使用索引
