SQL
1 查询语言 DQL
基本结构
SELECT
FROM
WHERE
GROUP BY
ORDER BY ;
1.1 单表查询
- 查询仅涉及一个表,是一种最简单的查询操作
选择表中的若干列
[例1] 查询全体学生的学号与姓名。
SELECT Sno,Sname
FROM Student;
[例3] 查询全体学生的详细记录。
SELECT Sno,Sname,Ssex,Sage,Sdept
FROM Student;
或
SELECT *
FROM Student;
查询经过计算的值
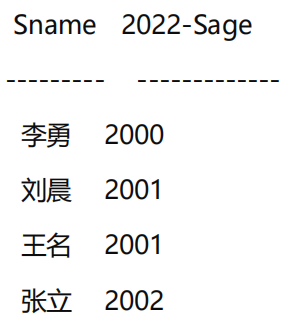
[例4] 查全体学生的姓名及其出生年份。
SELECT Sname,2022-Sage
FROM Student;
输出结果:
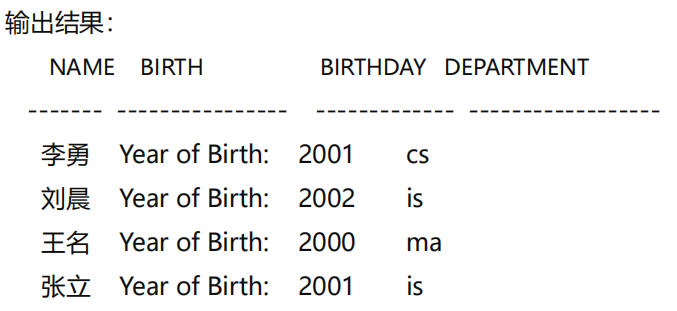
[例5] 查询全体学生的姓名、出生年份和所有系,要求用小写字母表示所有系名。
SELECT Sname , 2020-Sage AS 'Year of Birth: ' , LOWER(Sdept)
FROM Student;
使用列别名改变查询结果的列标题
SELECT Sname AS NAME,'Year of Birth: ’ AS BIRTH,2022-Sage AS BIRTHDAY,LOWER(Sdept) AS DEPARTMENT
FROM Student;
选择表中的若干元组
保留重复行
- 用ALL关键字
SELECT ALL Sno FROM SC; - ALL为默认关键字,可以省略,等价于:
SELECT Sno FROM SC;
消除取值重复的行
- 在SELECT子句中使用DISTINCT短语消除重复行
SELECT DISTINCT Sno FROM SC; - 注意 DISTINCT短语的作用范围是所有目标列
例:查询选修课程的各种成绩
错误的写法
SELECT DISTINCT Cno,DISTINCT Grade FROM SC;
正确的写法
SELECT DISTINCT Cno,Grade FROM SC;
用where子句查询满足条件的元祖
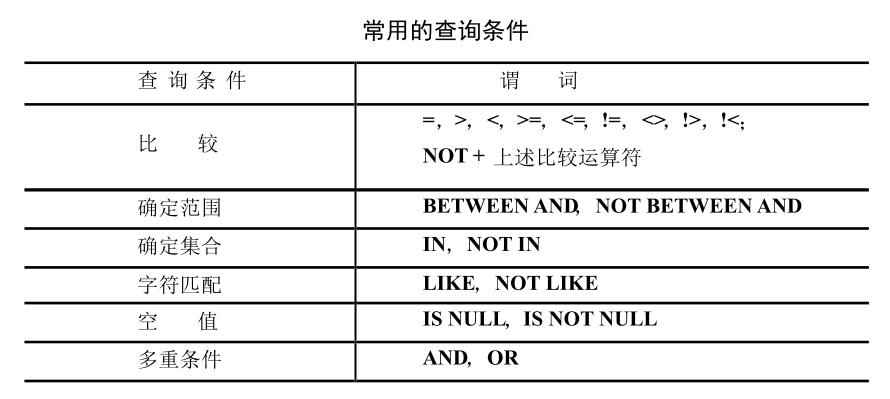
比较大小
- 在WHERE子句的比较条件中使用比较运算符 = ,>,<,>=,<=,!= 或 <>,!>,!<,逻辑运算符NOT + 比较运算符
[例6] 查询所有年龄在20岁以下的学生姓名及其年龄。
SELECT Sname,Sage
FROM Student
WHERE Sage < 20;
确定范围
- 使用谓词 BETWEEN … AND … NOT BETWEEN … AND …
[例7] 查询年龄在20~23岁(包括20岁和23岁)之间的学生的姓名、系别和年龄。
SELECT Sname,Sdept,Sage
FROM Student
WHERE Sage BETWEEN 20 AND 23;
确定集合
-
使用谓词 IN <值表>, NOT IN <值表>
<值表>:用逗号分隔的一组取值[例9] 查询既不是信息系、数学系,也不是计算机科学系的学生的姓名和性别。
SELECT Sname,Ssex
FROM Student
WHERE Sdept NOT IN ( 'IS','MA','CS' );
字符串匹配
-
WHERE 子句中可以对字符串进行模版匹配,形如:
WHERE <Attribute> LIKE <pattern> or <Attribute> NOT LIKE <pattern>
其中<pattern>是匹配模板,即:固定字符串或含通配符的字符串- 通配符:
% (百分号) 代表任意长度(长度可以为0)的字符串
_ (下横线) 代表任意单个字符
[例10] 查询学号为95001的学生的详细情况。
SELECT FROM Student
WHERE Sno LIKE '95001';
等价于:
SELECT FROM Student
WHERE Sno = '95001';
[例11] 查询所有姓刘学生的姓名、学号和性别。
SELECT Sname,Sno,Ssex
FROM Student
WHERE Sname LIKE ‘刘%’;[例12] 查询姓"欧阳"且全名为三个汉字的学生的姓名。
SELECT Sname
FROM Student
WHERE Sname LIKE '欧阳__';[例13] 查询名字中第2个字为"阳"字的学生的姓名和学号
SELECT Sname,Sno
FROM Student
WHERE Sname LIKE '__阳%';[例14] 查询所有不姓刘的学生姓名。
SELECT Sname,Sno,Ssex
FROM Student
WHERE Sname NOT LIKE '刘%'; - 通配符:
-
当用户要查询的字符串本身就含有 % 或 时,要使用ESCAPE '<换码字符>' 短语对通配符进行转义。(! Mysql不能用\作为转义符)
[例15] 查询DB_Design课程的课程号和学分。
SELECT Cno,Ccredit
FROM Course
WHERE Cname LIKE 'DB\_Design'
ESCAPE '\'
[例16] 查询以“DB”开头,且倒数第3个字符为 i 的课程的详细情况。
SELECT
FROM Course
WHERE Cname LIKE ‘DB_%i_ _' ESCAPE '*'; -
当进行固定字符串匹配时用可以‘=’代替‘like’
-
对于包含单引号的字符串,在条件表达式中用双引号代替单引号
[例16] 查询课程名为‘数据库’的课程的详细情况。
SELECT *
FROM Course
WHERE Cname = "'数据库'" ;
多重条件查询
-
用逻辑运算符AND,OR和 NOT来联结多个查询条件
[例17] 查询计算机系年龄在20岁以下的学生姓名。
SELECT Sname
FROM Student
WHERE Sdept= 'CS' AND Sage<20;[例18] 查询信息系(IS)、数学系(MA)和计算机科学系(CS)学生的姓名和性别。
SELECT Sname,Ssex
FROM Student
WHERE Sdept IN ( 'IS','MA','CS' )
可改写为:
SELECT Sname,Ssex
FROM Student
WHERE Sdept= ' IS ' OR Sdept= ' MA' OR Sdept= ' CS ';[例19]查询年龄在20~23岁(包括20岁和23岁)之间的学生的姓名、系别和年龄。
SELECT Sname,Sdept,Sage
FROM Student
WHERE Sage BETWEEN 20 AND 23;
可改写为:
SELECT Sname,Sdept,Sage
FROM Student
WHERE Sage>=20 AND Sage<=23;
涉及空值的查询
-
测试是否空值需用谓词 IS NULL 或 IS NOT NULL
[例20] 某些学生选修课程后没有参加考试,所以有选课记录,但没有考试成绩。查询缺少成绩的学生的学号和相应的课程号。
SELECT Sno,Cno FROM SC
WHERE Grade IS NULL;[例21] 查所有有成绩的学生学号和课程号。
SELECT Sno,Cno
FROM SC
WHERE Grade IS NOT NULL;
对查询结果进行排序
-
使用ORDER BY子句
- 可以按一个或多个属性列排序
- 升序:ASC;降序:DESC;缺省值为升序
-
当排序列含空值时
- ASC:排序列为空值的元组最后显示
- DESC:排序列为空值的元组最先显示
-
Order子句只能出现在select语句的最后部分
[例22] 查询选修了3号课程的学生的学号及其成绩,查询结果按分数降序排列。
SELECT Sno,Grade
FROM SC
WHERE Cno= ' 3 '
ORDER BY Grade DESC;[例23] 查询全体学生情况,查询结果按所在系的系号升序排列,同一系中的学生按年龄降序排列。
SELECT *
FROM Student
ORDER BY Sdept,Sage DESC;
1.2 聚集和分组
聚集-集函数
只有select和having能使用集函数
在Select子句中可以使用集函数,对指定的列进行聚合计算
-
计数 COUNT([DISTINCT|ALL] <列名> | *)
-
计算总和 SUM ([DISTINCT|ALL] <列名>)
-
计算平均值 AVG([DISTINCT|ALL] <列名>)
-
求最大值 MAX([DISTINCT|ALL] <列名>)
-
求最小值 MIN([DISTINCT|ALL] <列名>)
-
DISTINCT短语:在计算时要取消指定列中的重复值
-
ALL短语:不取消重复值
-
ALL为缺省值
[例24] 查询学生总人数。
SELECT COUNT(*)
FROM Student;[例25] 查询选修了课程的学生人数。
SELECT COUNT(DISTINCT Sno)
FROM SC;
注:用DISTINCT以避免重复计算学生人数[例26] 计算1号课程的学生平均成绩。
SELECT AVG(Grade)
FROM SC
WHERE Cno= ' 1 ';[例27] 查询选修1号课程的学生最高分数。
SELECT MAX(Grade)
FROM SC
WHER Cno= ' 1 '; -
集函数中的空值NULL
- 空值不加入SUM、AVG和COUNT的计算,也不会成为列中的MIN、MAX值
- 但如果列中没有非空值,则集函数结果会返回空值

SELECT count(*)
FROM SC
WHERE Cno = ‘1001’;
VS
SELECT count(Grade)
FROM SC
WHERE Cno = ‘1001’;
2 VS 1若数据: Grade = {NULL, NULL, NULL}
SELECT SUM(Grade) FROM SC; -- 结果: NULL
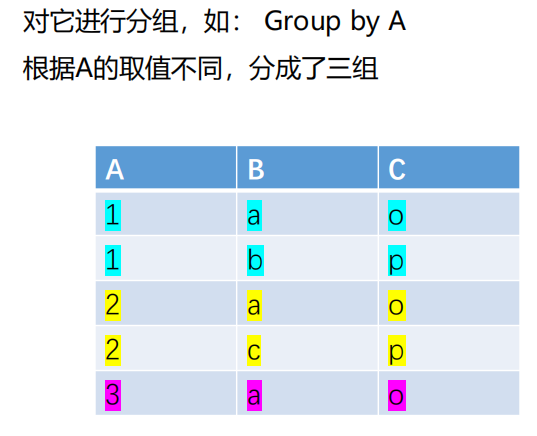
分组
group by
- 使用GROUP BY子句分组
- 细化集函数的作用对象
- 未对查询结果分组时,集函数将作用于整个查询结果
- 对查询结果分组后,集函数将分别作用于每个组
- GROUP BY子句的作用对象是查询的中间结果表
- 分组方法:按指定的一列或多列值分组,值相等的为一组
- 使用GROUP BY子句后,SELECT子句的列名列表中只能出现分组属性和集函数
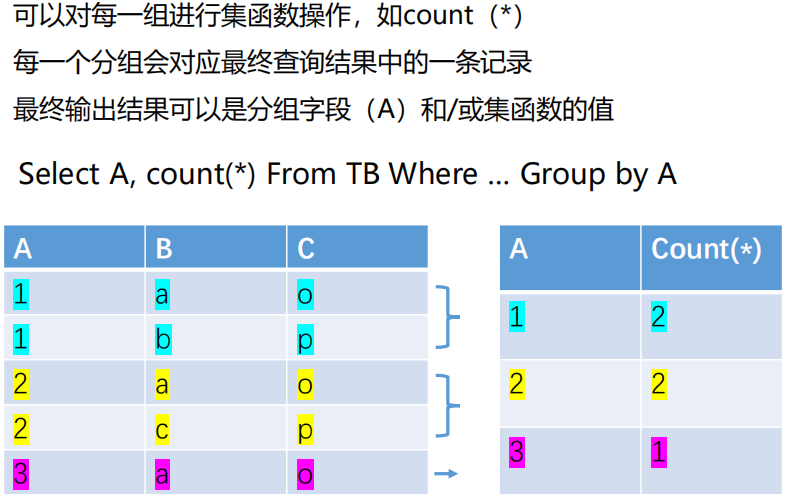
[例28] 求各个课程号及相应的选课人数。
SELECT Cno,COUNT(Sno)
FROM SC
GROUP BY Cno;

having
-
只有满足HAVING短语指定条件的组才输出
-
HAVING短语与WHERE子句的区别:作用对象不同
- WHERE子句作用于基表或视图,从中选择满足条件的元组
- HAVING短语作用于组,从中选择满足条件的组。
-
HAVING子句中出现的列只能是在group by子句或集函数中出现的列
[例30] 查询选修了3门以上课程的学生学号。
SELECT Sno
FROM SC
GROUP BY Sno
HAVING COUNT(*) >3;[例31] 查询有3门以上课程是90分以上的学生的学号及(90分以上的)课程数
SELECT Sno, COUNT(*)
FROM SC
WHERE Grade>=90
GROUP BY Sno
HAVING COUNT(*)>=3;
1.3 多表查询
-
在From子句中涉及
-
和自己连接:自身连接
-
和其他表连接
- 不带连接谓词:广义笛卡尔积
- 带连接谓词
- 不满足连接条件的元组一并输出:外链接
- 只输出满足连接条件的元祖:内连接
- 非单一条件:复合条件连接
- 单一条件
- 等值:等值连接
- 不等值:非等值连接
广义笛卡尔积
- 是不带链接谓词的连接
- 一般格式是
SELECT <属性或表达式列表> FORM <表名> CROSS JOIN <表名> - 例
SELECT Student.*, SC.* FROM Student, SC
等值连接
- 语法:
[<表名1>.]<列名1> = [<表名2>.]<列名2>- 任何子句中引用表1和表2中同名属性时,都必须加表名前缀。
- 引用唯一属性名时可以加也可以省略表名前缀。
[例32] 查询每个学生及其选修课程的情况。
SELECT Student.sno,sname, cno
FROM Student,SC
WHERE Student.Sno = SC.Sno;
自然连接
等值连接的一种特殊情况,把目标列中重复的属性列去掉
非等值连接查询
连接运算符不是=号的连接
内连接
传统的连接操作被称为内连接(INNER JOIN),其一般格式是:
SELECT <属性或表达式列表>
FROM <表名> [INNER] JOIN <表名>
ON <连接条件>
[WHERE <限定条件>]
- 上式中INNER可以省略,这里用ON短语指定连接条件,用WHERE短语指定其它限定条件。
自身连接查询
- 一个表与其自己进行连接
- 需要给表的两个副本起别名以示区别
- 由于所有属性名都是同名属性,因此必须使用别名前缀
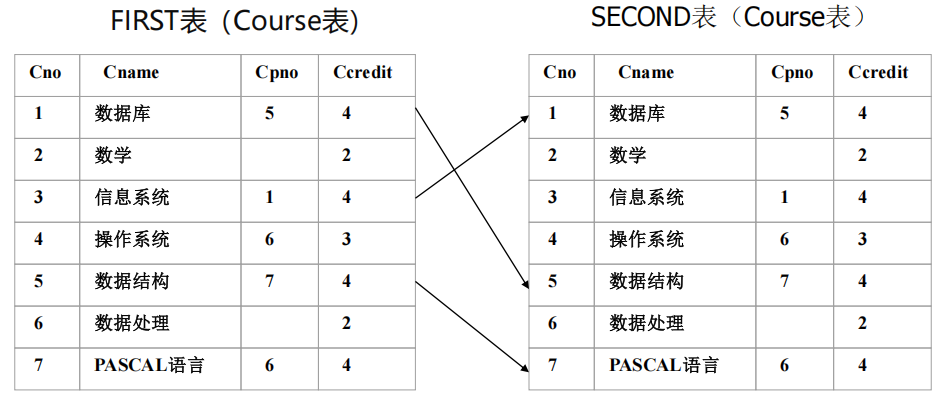
[例33] 查询每一门课的间接先修课(即先修课的先修课)
SELECT FIRST.Cno,SECOND.Cpno
FROM Course AS FIRST,Course AS SECOND
WHERE FIRST.Cpno = SECOND.Cno;
外连接查询
普通连接操作只输出满足连接条件的元组;外连接操作以指定表为连接主体,将主体表中不满足连接条件的元组一并输出
-
语法
SELECT <属性或表达式列表>
FROM <表名> [LEFT | RIGHT | FULL] [OUTER] JOIN <表名>
ON <连接条件>
[WHERE <限定条件>] -
Mysql不支持全外连接
解决方法:Left join Union Right join
[例34] 查询每个学生及其选修课程的情况包括没有选修课程的学生----用外连接操作
SELECT Student.Sno,Sname,Cno,Grade
FROM Student Left Join SC
on Student.Sno =SC.Sno;
复合条件连接查询
WHERE子句中含多个连接条件时,称为复合条件连接
[例34] 查询选修2号课程且成绩在90分以上的所有学生的学号、姓名
SELECT Student.Sno, student.Sname
FROM Student, SC
WHERE Student.Sno = SC.Sno AND / 连接谓词/
SC.Cno= ' 2 ' AND /* 其他限定条件 */
SC.Grade > 90;/* 其他限定条件 */
1.4 子查询
- 一个SELECT-FROM-WHERE语句称为一个查询块
- 子查询一定要跟在比较符之后(p26)
错误的例子:
SELECT Sno,Sname,Sdept
FROM Student
WHERE ( SELECT Sdept
FROM Student
WHERE Sname= ‘ 刘晨 ’ )
= Sdept;
正确的例子:
SELECT Sno, Sname, Sdept
FROM Student
WHERE Sdept = ( SELECT Sdept -- 子查询跟在比较符 '=' 之后
FROM Student
WHERE Sname = ' 刘晨 ' ); -- 比较符之后是子查询
子查询分类
- 可以嵌套在另一个查询块的WHERE子句或HAVAING短语的条件中
SELECT Sname FROM Student WHERE Sno IN 外层查询/父查询
(SELECT Sno FROM SC WHERE Cno= ' 2 ');内层查询/子查询 - 可以插入到FROM子句中,作为临时表使用
- 临时表需起个别名来引用
- 不是所有数据库产品都支持临时表
SELECT SIS.Sno, Sname, Cno
FROM SC, (SELECT Sno, Sname from Student WHERE Sdept= ‘ IS ‘) as SIS
WHERE SC.Sno=SIS.Sno
- 可以插入到SELECT子句中
- 确保返回结果为单列单行
- 没有太大意义,多数数据库不支持
引出子查询的谓词
IN
[例35] 查询与“刘晨”在同一个系学习的学生。
此查询可以分步来完成
- 确定“刘晨”所在系名(是‘IS’系)
SELECT Sdept FROM Student
WHERE Sname= ' 刘晨 ‘; - 查找所有在IS系学习的学生。
SELECT Sno,Sname,Sdept
FROM Student
WHERE Sdept= ' IS ';
[例36] 查询与“刘晨”在同一个系学习的学生。
也可以直接构造嵌套查询:将第一步查询嵌入到第二步查询的条件中
SELECT Sno,Sname,Sdept FROM Student
WHERE Sdept IN
(SELECT Sdept FROM Student
WHERE Sname= ‘ 刘晨 ’);
此查询为不相关子查询
[例37]. 查询选修了课程名为“信息系统”的学生学号和姓名
SELECT Sno,Sname ③ 最后在Student关系中取出Sno和Sname
FROM Student
WHERE Sno IN
(SELECT Sno ② 然后在SC关系中找出选修了3号课程的学生学号
FROM SC
WHERE Cno IN
(SELECT Cno ① 首先在Course关系中找出“信息系统”的课程号,结果为3号
FROM Course
WHERE Cname= ‘信息系统’));
或
SELECT Sno,Sname
FROM Student,SC,Course
WHERE Student.Sno = SC.Sno AND
SC.Cno = Course.Cno AND
Course.Cname=‘信息系统’;
比较运算符
当能确切知道内层查询返回单值时,可用比较运算符 (>, <, =, >=, <=, != (或 <>))。
假设一个学生只可能在一个系学习,并且必须属于一个系,则在
[例36]中可以用 = 代替IN
SELECT Sno,Sname,Sdept FROM Student
WHERE Sdept =
SELECT Sdept FROM Student
WHERE Sname= ' 刘晨 ';
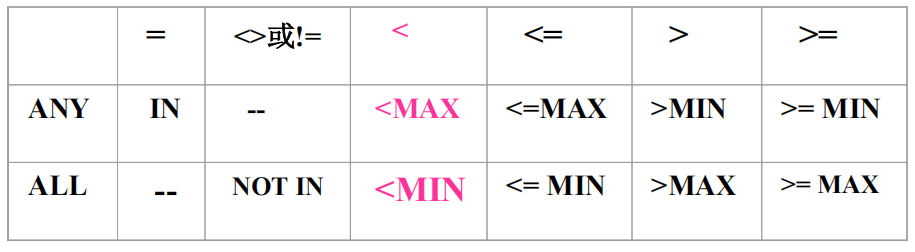
ANY或ALL
- ANY:任意一个值
- ALL:所有值
- 与比较运算符配合使用

[例38] 查询其他系中比信息系任意一个(其中某一个)学生年龄小的学生姓名和年龄
SELECT Sname,Sage
FROM Student
WHERE Sage < ANY (SELECT Sage
FROM Student
WHERE Sdept= ' IS ')
AND Sdept <> ' IS ' ;
/ 注意这是父查询块中的条件 /
- ANY和ALL谓词有时可以用集函数实现
- 用集函数实现子查询通常比直接用ANY或ALL查询效率要高,因为前者通常能够减少比较次数
[例39] 用集函数实现 [例38] 的查询
SELECT Sname,Sage
FROM Student
WHERE Sage <
(SELECT MAX(Sage)
FROM Student
WHERE Sdept= ' IS ')
AND Sdept <> ' IS ’;
[例40] 查询其他系中比信息系所有学生年龄都小的学生姓名及年龄。
方法一:用ALL谓词
SELECT Sname,Sage
FROM Student
WHERE Sage < ALL
(SELECT Sage
FROM Student
WHERE Sdept= ' IS ')
AND Sdept <> ' IS ’;
方法二:用集函数
SELECT Sname,Sage
FROM Student
WHERE Sage <
(SELECT MIN(Sage)
FROM Student
WHERE Sdept= ' IS ')
AND Sdept <>' IS ’;
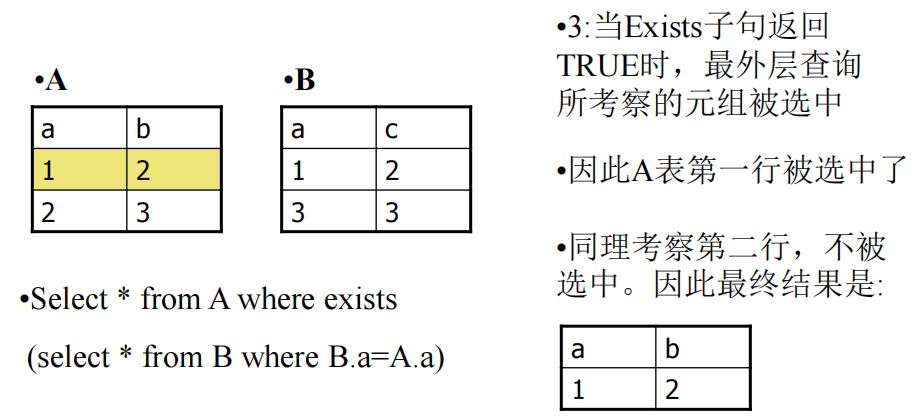
EXISTS

-
用于相关子查询
[例41] 查询所有选修了1号课程的学生姓名。
SELECT Sname
FROM Student
WHERE EXISTS
(SELECT *
FROM SC /*相关子查询*/
WHERE Sno=Student.Sno AND
Cno= ' 1 '); -
用于不相关子查询
select from a where exists (select from b) -
一些带EXISTS或NOT EXISTS谓词的子查询不能被其他形式的子查询等价替换
- 用EXISTS/NOT EXISTS实现全称量词,
[例42] 查询选修了全部课程的学生姓名。
SELECT Sname FROM Student
WHERE NOT EXISTS
(SELECT FROM Course
WHERE NOT EXISTS
(SELECT FROM SC
WHERE Sno= Student.Sno
AND Cno= Course.Cno)); - 用EXISTS/NOT EXISTS实现蕴含逻辑,
[例43] 查询至少选修了学生95002选修的全部课程的学生号码-
用逻辑蕴函表达:查询学号为x的学生,对所有的课程y,只要95002学生选修了课程y,则x也选修了y。
-
形式化表示:
用P表示谓词 “学生95002选修了课程y”
用q表示谓词 “学生x选修了课程y”
则上述查询为:
变换后语义:不存在这样的课程y,学生95002选修了y,而学生x没有选。

-
- 用EXISTS/NOT EXISTS实现全称量词,
-
所有带IN谓词、比较运算符、ANY和ALL谓词的子查询都能用带EXISTS谓词的子查询等价替换。
[例36] 中的IN查询可以用带EXISTS谓词的子查询替换:
SELECT Sno,Sname,Sdept
FROM Student S1
WHERE EXISTS
(SELECT *
FROM Student S2
WHERE S2.Sdept = S1.Sdept AND
S2.Sname = ' 刘晨 ');
1.5 集合查询
- 并操作 ( subquery ) UNION ( subquery )
- 交操作 ( subquery ) INTERSECT ( subquery )
- 差操作 ( subquery ) EXCEPT ( subquery )
[例44] 查询计算机科学系的学生及年龄不大于19岁的学生。
SELECT
FROM Student
WHERE Sdept= 'CS'
UNION
SELECT
FROM Student
WHERE Sage<=19;
[例45] 查询计算机科学系选修95001号课程的学生的学号。
SELECT Sno
FROM Student
WHERE Sdept= 'CS'
Intersect
SELECT Sno
FROM SC
WHERE Cno=‘95001’;
[例46] 查询计算机科学系没有选修95001号课程的学生的学号。
SELECT Sno
FROM Student
WHERE Sdept= 'CS'
Except
SELECT Sno
FROM SC
WHERE Cno=‘95001’;
2 定义语言 DDL
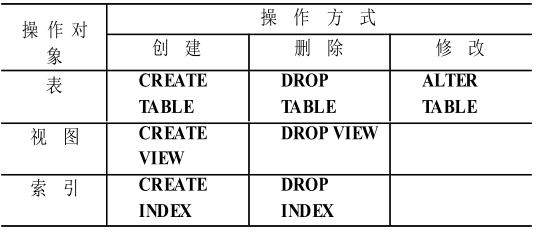
- 数据库模式(schema)主要由数据库中关系(relation)的声明构成,还包括视图(view)、索引(index)、触发器(trigger)等对象
- 对数据库模式的定义通过SQL语言中的数据定义语言(Data Definition Language)部分来完成
- DDL语言完成数据库对象的创建、删除和修改
2.1 定义基本表
语法
CREATE TABLE <表名>(
<列名> <数据类型>[ <列级完整性约束条件> ]
[,<列名> <数据类型>[ <列级完整性约束条件>] ] …
[,<表级完整性约束条件> ]
);
常见的数据类型
- INT or INTEGER
- REAL or FLOAT
- CHAR(n ) = 定长字符串
- VARCHAR(n ) = 变长字符串,n是字符串最大长度
- DATE, TIME, and DATETIME
常用完整性约束
- 主键约束: PRIMARY KEY
- 唯一性约束:UNIQUE
- 非空值约束:NOT NULL
- 参照完整性约束: REFERENCES
例
[例1] 建立一个“学生”表Student,它由学号Sno、姓名Sname、性别Ssex、年龄Sage、所在系Sdept五个属性组成。其中学号不能为空,值是唯一的,并且姓名取值也唯一。
CREATE TABLE Student
(Sno CHAR(5) NOT NULL UNIQUE,
Sname CHAR(20) UNIQUE,
Ssex CHAR(1) ,
Sage INT,
Sdept VARCHAR(15));
[例2] 建立一个“学生选课”表SC,它由学号Sno、课程号Cno,修课成绩Grade组成,其中(Sno, Cno)为主键。
CREATE TABLE SC(
Sno CHAR(5) ,
Cno CHAR(3) ,
Grade int,
Primary key (Sno, Cno));
2.2 删除基本表
- 语法:DROP TABLE <表名>;
[例3] 删除Student表
DROP TABLE Student ;
2.3 修改基本表
语法
ALTER TABLE <表名>
[ ADD <新列名> <数据类型> [ 完整性约束 ] ]
[ DROP <完整性约束名> ]
[ MODIFY <列名> <数据类型> ];
例
[例4] 向Student表增加“入学时间”列,其数据类型为日期型。
ALTER TABLE Student ADD Scome DATE;
[例5] 删除属性列
ALTER TABLE Student Drop Sage;
[例6] 将年龄的数据类型改为半字长整数。
ALTER TABLE Student MODIFY Sage SMALLINT;
[例7] 删除学生姓名必须取唯一值的约束。
ALTER TABLE Student DROP UNIQUE(Sname);
3 操纵语言 DML
- 三种数据更新类型
- Insert 插入一条或多条元组
- Update 更新现有一条或多条元组中的值
- Delete 删除一条或多条元组
3.1 插入数据
插入单条元组
语法
INSERT
INTO <表名> [(<属性列1>[,<属性列2 >…)]
VALUES (<常量1> [,<常量2>] … )
例
[例7] 将一个新学生记录
(学号:95020;姓名:陈冬;性别:男;所在系:IS;年龄:18岁)插入到Student表中。
INSERT INTO Student
VALUES ('95020', '陈冬' , '男' ,'IS',18);
[例8] 插入一条选课记录( '95020','1 ')。
INSERT INTO SC(Sno,Cno)
VALUES (' 95020 ',' 1 ');
新插入的记录在Grade列上取空值
插入子查询结果
语法
INSERT
INTO <表名> [(<属性列1> [,<属性列2>… )]
子查询;
- 功能:将子查询结果插入指定表中
- INTO子句(与插入单条元组类似)
- 指定要插入数据的表名及属性列
- 属性列的顺序可与表定义中的顺序不一致
- 没有指定属性列:表示要插入的是一条完整的元组
- 指定部分属性列:插入的元组在其余属性列上取空值
- 子查询
SELECT子句目标列必须与INTO子句匹配- 值的个数
- 值的类型
例
[例9] 对每一个系,求学生的平均年龄,并把结果存入数据库。
第一步:建表
CREATE TABLE Deptage
(Sdept CHAR(15), Avgage SMALLINT)
第二步:插入数据
INSERT INTO Deptage(Sdept,Avgage)
SELECT Sdept,AVG(Sage)
FROM Student
GROUP BY Sdept
3.2 修改数据
- 语句格式
UPDATE <表名>
SET <列名>=<表达式>[,<列名>=<表达式>]…
[WHERE <条件>];
-
SET子句
- 指定修改方式
- 要修改的列
- 修改后取值
- 指定修改方式
-
WHERE子句
- 指定要修改的元组
- 缺省表示要修改表中的所有元组
-
功能
修改指定表中满足WHERE子句条件的元组 -
三种修改方式
- 修改某一个元组的值
- 修改多个元组的值
- 带子查询的修改语句
修改某一个元组的值
[例10] 将学生95001的年龄改为22岁。
UPDATE Student
SET Sage=22
WHERE Sno=' 95001 ';
修改多个元组的值
[例11] 将所有学生的年龄增加1岁。
UPDATE Student
SET Sage = Sage+1;
带子查询的修改语句
[例12] 将计算机科学系全体学生的成绩置零。
UPDATE SC
SET Grade=0
WHERE 'CS'=
(SELECT Sdept
FROM Student
WHERE Student.Sno = SC.Sno);
3.3 删除数据
- 语法格式
DELETE FROM <表名> [WHERE <条件>];
-
功能
删除指定表中满足WHERE子句条件的元组 -
WHERE子句
指定要删除的元组
缺省表示要修改表中的所有元组 -
三种删除方式
- 删除某一个元组的值
[例13] 删除学号为95019的学生记录。
DELETE
FROM Student
WHERE Sno='95019'; - 删除多个元组的值
[例14] 删除2号课程的所有选课记录。
DELETE
FROM SC
WHERE Cno='2';
[例15] 删除所有的学生选课记录。
DELETE
FROM SC; - 带子查询的删除语句
[例16] 删除计算机科学系所有学生的选课记录。
DELETE
FROM SC
WHERE 'CS'=
(SELETE Sdept
FROM Student
WHERE Student.Sno=SC.Sno);
- 删除某一个元组的值
4 控制语言 DCL
- 创建角色:
Create Role roleA;
当前用户需具备创建角色的权限 - 向角色逐个授予权限
Grant insert, delete on tableA to roleA; Grant execute on procedureA to roleA - 将角色赋予指定用户
Grant roleA to UserA- 此时UserA就继承了roleA的权限
- 也可以对用户UserA赋予roleA之外的权限
5 视图
5.1 视图定义
CREATE VIEW
<视图名> [(<列名> [,<列名>]…)]
AS <子查询>
[WITH CHECK OPTION];
例
建立新视图
[例17] 建立信息系学生的视图
CREATE VIEW IS_Student
AS
SELECT Sno,Sname,Sage
FROM Student
WHERE Sdept= 'IS';
[例18] 建立信息系选修了1号课程的学生视图。
CREATE VIEW IS_S1(Sno,Sname,Grade)
AS
SELECT Student.Sno,Sname,Grade
FROM Student,SC
WHERE Sdept= 'IS' AND
Student.Sno=SC.Sno AND
SC.Cno= '1';
基于视图建立新视图
[例19] 建立信息系选修了1号课程且成绩在90分以上的学生的视图。
CREATE VIEW IS_S2
AS
SELECT Sno,Sname,Grade
FROM IS_S1
WHERE Grade>=90;
带表达式的视图
[例20] 定义一个反映学生出生年份的视图。
CREATE VIEW BT_S(Sno,Sname,Sbirth)
AS
SELECT Sno,Sname,2000-Sage
FROM Student
设置一些派生属性列, 也称为虚拟列--Sbirth
带表达式的视图必须明确定义组成视图的各个属性列名
带分组的视图
[例21] 将学生的学号及他的平均成绩定义为一个视图
假设SC表中“成绩”列Grade为数字型
CREAT VIEW S_G(Sno,Gavg)
AS
SELECT Sno,AVG(Grade)
FROM SC
GROUP BY Sno;
不建议以 SELECT * 方式创建视图,因这样创建的视图可扩展性差
[例22]将Student表中所有女生记录定义为一个视图
CREATE VIEW
F_Student1(stdnum,name,sex,age,dept)
AS SELECT *
FROM Student
WHERE Ssex='女';
缺点:当修改基表Student的结构后,Student表与F_Student1视图的映象关系会被破坏,导致该视图不能正确工作。
[例23]将Student表中所有女生记录定义为一个视图
CREATE VIEW
F_Student2 (stdnum,name,sex,age,dept)
AS SELECT Sno,Sname,Ssex,Sage,Sdept
FROM Student
WHERE Ssex='女';
为基表Student增加属性列不会破坏Student表与F_Student2视图的映象关系。
5.2 With Check Option
透过视图进行增删改操作时,不得破坏视图定义中的谓词条件(即子查询中的条件表达式)
[例25] 建立信息系学生的视图。
CREATE VIEW IS_Student
AS
SELECT *
FROM Student
WHERE Sdept= 'IS’
WITH CHECK OPTION
没有
WITH CHECK OPTION时,如果插入(95008, '韩萍', 20, 'CS'),不会报错
事务管理与恢复
1 事务管理
并发操作带来的数据不一致性
-
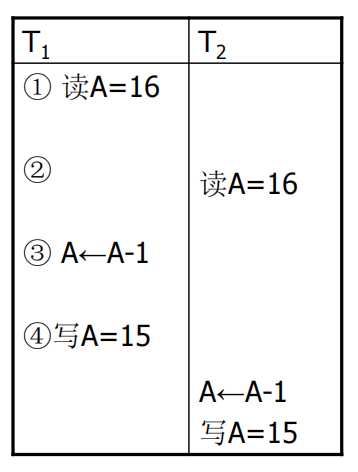
丢失修改(lost update)
丢失修改是指事务1与事务2从数据库中读入同一数据并修改,事务2的提交结果破坏了事务1提交的结果,导致事务1的修改被丢失。
-
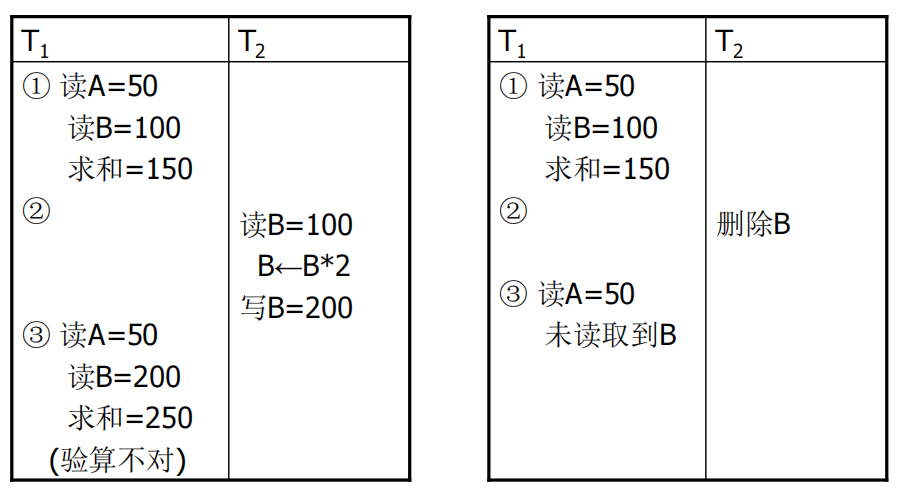
不可重复读(non-repeatable read)
不可重复读是指事务1读取数据后,事务2执行更新操作,使事务1无法再现前一次读取结果。三种不可重复读:事务1读取某一数据后
- 事务2对其做了修改,当事务1再次读该数据时,得到与前一次不同的值。
- 事务2删除了其中部分记录,当事务1再次读取数据时,发现某些记录神密地消失了。
- 事务2插入了一些记录,当事务1再次按相同条件读取数据时,发现多了一些记录。
- 后两种不可重复读有时也称为幻影现象(phantom row)
-
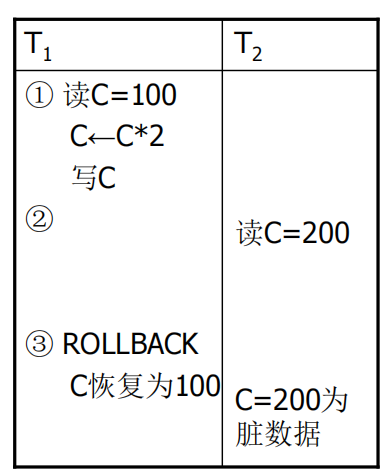
读“脏”数据(dirty read)
事务1修改某一数据,并将其写回磁盘。事务2读取同一数据后,事务1由于某种原因被撤消,这时事务1已修改过的数据恢复原值,事务2读到的数据就与数据库中的数据不一致,是不正确的数据,又称为“脏”数据
调度——冲突可串行化、可恢复的调度、级联回滚、无级联调度
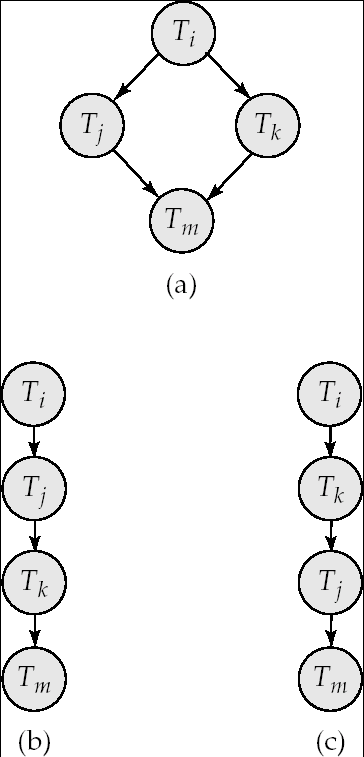
冲突可串行化
-
冲突指令:现有事务
-
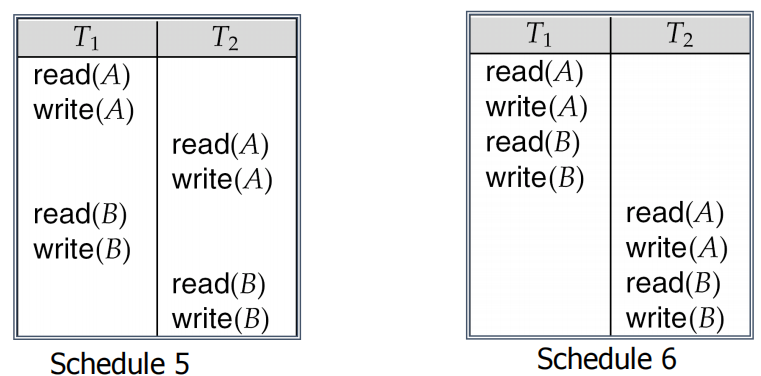
如果一个调度S可以通过一系列的非冲突指令顺序调换而被转换为另一个调度S’, 且S’是一个串行化调度,这时我们说S是冲突可串行化的( conflict serializable )
-
调度5 可以转换为串行调度调度6,它是冲突可串行化的
-
冲突不可串行化的例子:我们对下面的调度无法通过指令调换来获得等价的串行调度 < T3 , T4 >,或< T4 , T3 >

用前趋图检查冲突可串行化
- 顶点是事务的名称
- 对于两个顶点:事务Ti 和 Tj , 如果这两个事务冲突,且是事务Ti 先访问的冲突资源,则画一个 从Ti到Tj的弧。
- 可以在弧上标注冲突资源的名称

- 用前趋图检查冲突可串行性
- 当且仅当前驱图是无环的时候,对应的调度是冲突可串行的
- 当前驱图是无环的时候,冲突等价的串行化调度的事务执行顺序可以通过对图的拓扑排序( topological sorting )方法获得
- 例如通过拓扑排序,可知前例调度8的串行化调度顺序可以是: T5 → T1 → T3 →T2 → T4
可恢复的调度、级联回滚、无级联调度
- 可恢复的调度
- 若事务Tj 读取了一个事务Ti 之前写入的数据,
- 则 Ti 的提交操作应在Tj 的提交操作之前发生
- 可以避免前述数据回滚导致的不一致问题
- 级联回滚
调度10是可恢复的调度。但若T10失败了,则它需要回滚。而T10的回滚会引起T11、T12的一连串回滚。这会导致事务运行不畅,数据库浪费大量计算资源
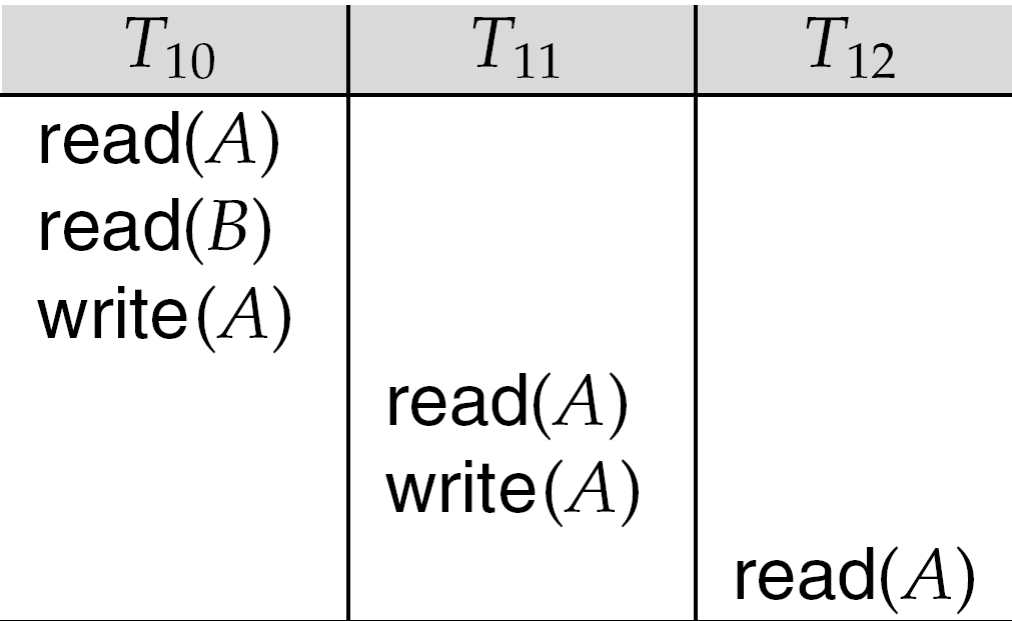
- 无级联调度(Cascadeless Schedules)
- 每一对事务若事务Tj 读取了一个事务Ti之前写入的数据,则 Ti 的提交操作应在Tj 的读取操作之前发生
- 无级联调度 ⊆ 可恢复调度
封锁方法
- 排它锁(X 写锁)
若事务T对数据对象A加上X锁,则只允许T读取和修改A,其它任何事务都不能再对A加任何类型的锁,直到T释放A上的锁 - 共享锁(S 读锁)
- 若事务T对数据对象A加上S锁,则其它事务只能再对A加S锁,而不能加X锁,直到T释放A上的S锁
- 这就保证了其他事务在T释放R上的S锁之前,只能读取R,而不能再对R作任何修改
三级封锁协议
一级封锁协议
- 写之前必须加X锁,直到事务结束才释放
二级封锁协议 - 在1级基础上,读之前必须加S锁,读完后即可释放S锁
三级封锁协议 - 在1级基础上,读之前必须加S锁,直到事务结束才释放
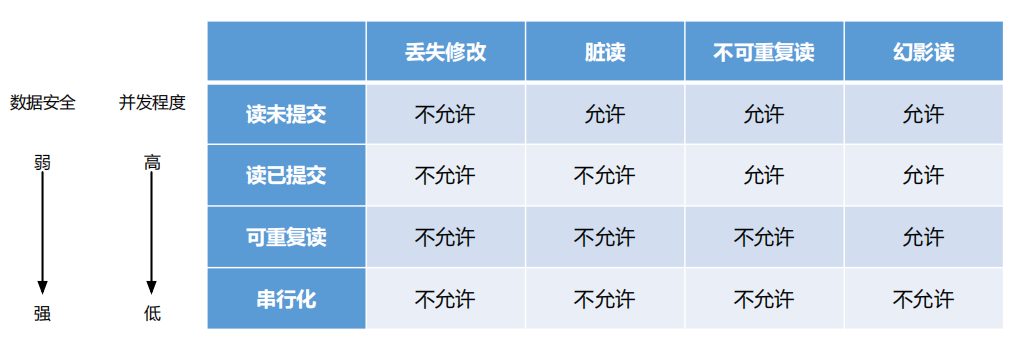
三级封锁协议与4种事务隔离级别
- 读未提交(Read Uncommited) -- 相当于1级封锁协议
当两个事务A、B同时进行时,即使A事务没有提交,所做的修改也会对B事务内的查询产生影响。对数据进行修改时,会加上共享锁。 - 读已提交(Read commited) -- 相当于2级封锁协议
只有在事务提交后,才会对另一个事务产生影响。 【多数数据库默认的隔离级别】 - 可重复读(Repeatable Read)-- 低于3级封锁协议
当两个事务同时进行时,其中一个事务修改数据对另一个事务不会造成影响,
即使修改的事务已经提交也不会对另一个事务造成影响。 - 串行化(SERIALIZABLE)-- 相当于3级封锁协议
两个事务同时进行时,一个事务读取的数据也会被锁定,不能被别的事务修改
两阶段封锁协议
-
两阶段锁协议内容
- 在对任何数据进行读、写操作之前,事务首先要获得对该数据的封锁
- 在释放一个封锁之后,事务不再获得任何其他封锁
-
“两段”锁的含义:事务分为两个阶段
- 第一阶段是获得封锁,也称为扩展阶段;
- 第二阶段是释放封锁,也称为收缩阶段。
-
对一组遵守两段锁协议的事务,可以实现可串行化调度,使得其并行执行的结果一定是正确的
-
另:事务遵守两段锁协议是可串行化调度的充分条件,但不是必要条件。即,可串行化的调度中,不一定所有事务都必须符合两段锁协议
-
两段锁协议可以解决所有数据不一致问题
严格的两阶段锁协议
- 两段锁协议不能解决级联回滚问题

- 解决方案:严格的两段锁协议( Strict Two-phase Locking)
- 在两阶段锁协议基础上,增加规则:事务获得的锁只有在事务结束时候才释放
- 第三级封锁协议与严格的两阶段锁协议一致
- 遵循第三级封锁协议的事务必然遵守两阶段锁协议
例
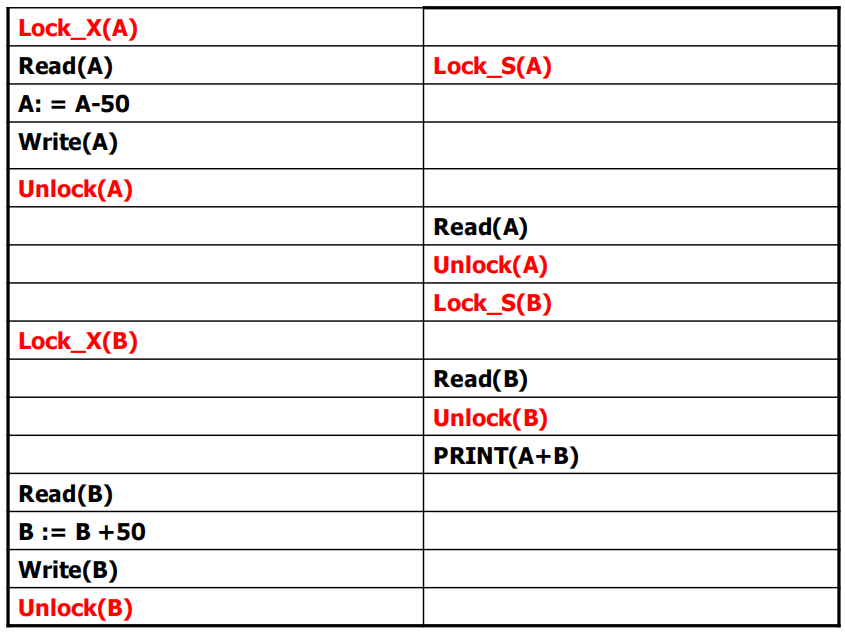
有写锁:至少一级
有读锁:至少二级
写锁不是事物结束才unlock:二级
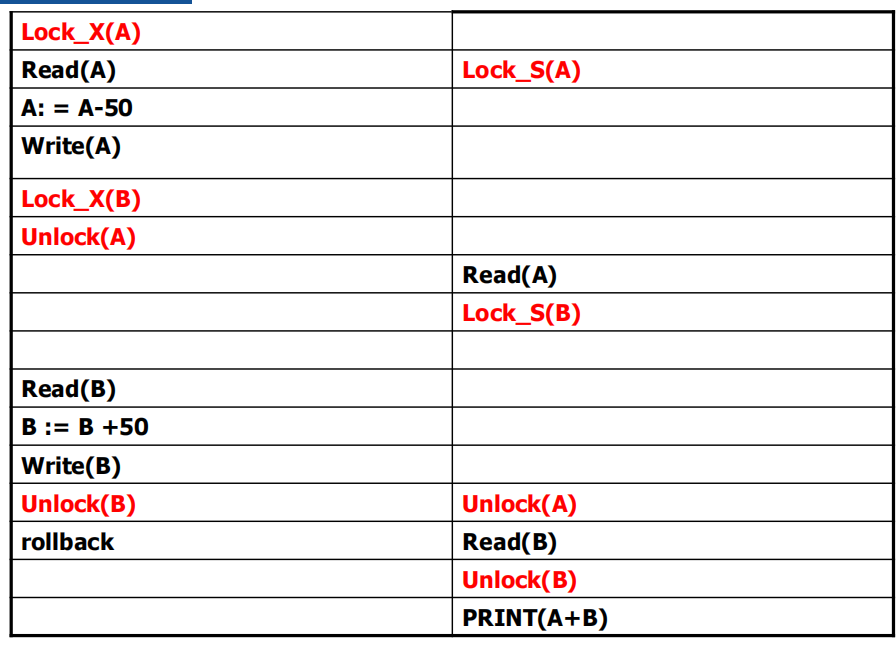
有写锁、读锁:至少二级
写锁不是事务结束才unlock:二级
加锁完了才解锁:两阶段锁
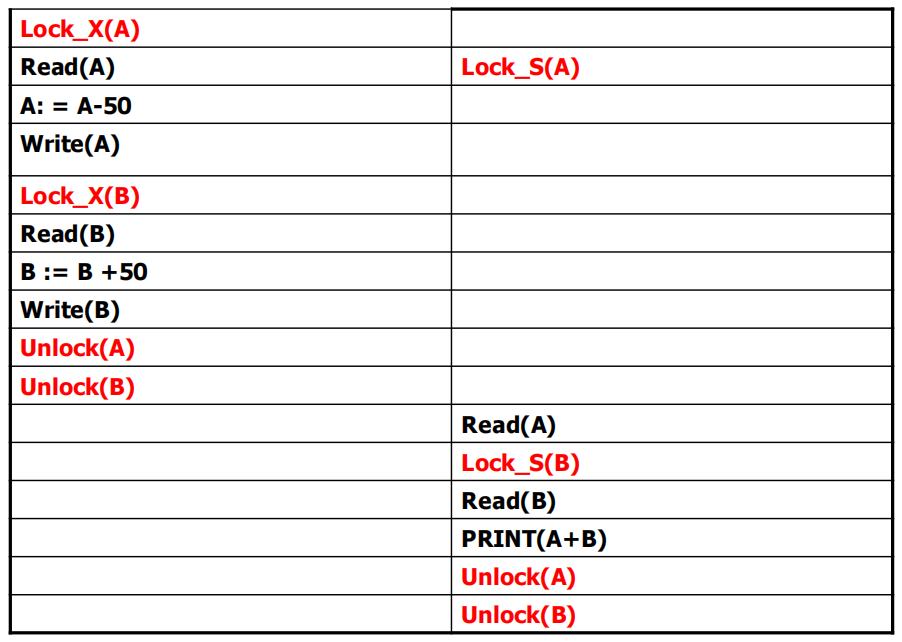
有写锁、读锁:至少二级
写锁在事务结束才unlock:三级
加锁完了才解锁:严格两阶段
例

S1
1------(A)----->2-(A)->4
└-(D)->3-(C)-->┘
冲突可串行;不可恢复,1写D,3读D,然后3提交1提交
S2
不可串行;可恢复
S3
可串行;可恢复

是,等价于r1(X) w1(X) r1(Y) w1(Y) r2(X) r2(Y) w2(Y)
不是(事物1在事物结束前提前释放了锁)
2 备份与恢复
2 恢复的实现技术
- 如何建立冗余数据
- 数据转储(backup)---或称数据备份
- 登录日志文件(logging)
- 如何利用这些冗余数据实施数据库恢复
2.1 数据转储
- 数据转储方法
- 静态转储与动态转储
- 全量转储与增量转储
2.2 登记日志文件
- 日志文件内容
- 各个事务的开始标记(BEGIN TRANSACTION)
- 各个事务的结束标记(COMMIT或ROLLBACK)
- 各个事务的所有更新操作
- 与事务有关的内部更新操作
- 日志文件作用
- 发生系统/介质故障时,利用日志文件进行故障恢复
- 故障时已提交事务进行重做(Redo)操作
- 故障时未提交事务进行撤销(Undo)操作
- 发生系统/介质故障时,利用日志文件进行故障恢复
2.3 缓冲区处理策略与日志/恢复策略的关系
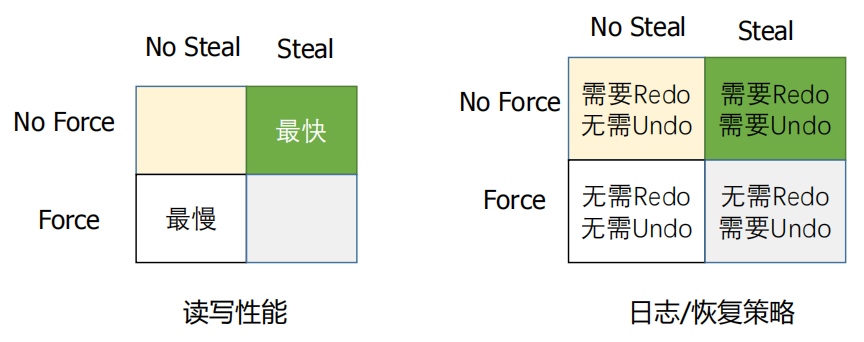
- 缓冲区处理策略
- Force: 内存中的数据最晚在commit的时候写入磁盘
- No Force: 内存中的数据可以一直保留,在commit之后过一段时间再写入磁盘(系统崩溃时数据可能还没写入磁盘,没能持久化)
- No Steal: 不允许在commit之前把内存中数据写入磁盘
- Steal:允许在事务commit之前把内存中的数据写入磁盘(系统崩溃时可能有未提交的数据被持久化了)
- 为提升数据读写性能,当前数据库常用No Force+Steal 策略
No Steal和Force模式的恢复
- 未提交事务不可以写入磁盘,提交事务必须写入磁盘
- 系统故障时,没有数据一致性问题,无需恢复
- 未提交的事务修改的数据页还停留在内存中,断电后重启,内存中的数据自然也就消失了,自动回滚
- 已经提交的事务,其修改的数据页已经写入到磁盘进行持久化,并没有受到影响
- 问题:每次事务都要进行磁盘随机写入(提交事务修改数据),性能很差
No Steal和No Force模式的恢复
- 未提交事务不可以写入磁盘,提交事务可以暂不写入磁盘
- 系统故障时
- 未提交事务并不会受到影响,自动回滚
- 已提交的事务的修改数据可能还未写入到数据文件中,日志文件与数据文件不一致,持久性未能保证
- 为此需引入Redo日志文件,解决内存数据丢失的问题,解决持久性问题
Steal和 Force模式的恢复
- 未提交事务可以写入磁盘,提交事务必须写入磁盘
- 系统故障时
- 已提交的事务,其修改的数据已经写入到磁盘进行持久化,并没有受到影响
- 未提交事务,其修改的数据可能已经被持久化到了数据文件中,日志文件与数据文件不一致
- 为此需引入Undo日志文件,清除数据文件中的未提交数据,解决原子性问题。
Steal和 No Force模式的恢复
- 未提交事务可以写入磁盘,提交事务可以暂不写入磁盘
- 性能最好
- 系统故障时
- 已提交的事务的修改数据可能还未写入到数据文件中
- 未提交事务,其修改的数据可能已经被持久化到了数据文件中
- 为此需引入Undo日志文件和Redo日志文件,共同解决数据原子性和持久性问题。
3 恢复的策略
3.1 基于Undo日志的恢复策略
保证事物的原子性
日志内容
<START T> : 标记事务的开始
<COMMIT T> : T 事务已经提交
<ABORT T> : T 事务已被回滚
<T,X,v> : T 事务已经更新数据项 X, 其更新前的旧值是 v
日志规则
- 更新操作:日志先写,数据文件后写
- Commit操作:数据文件先写,日志文件后写
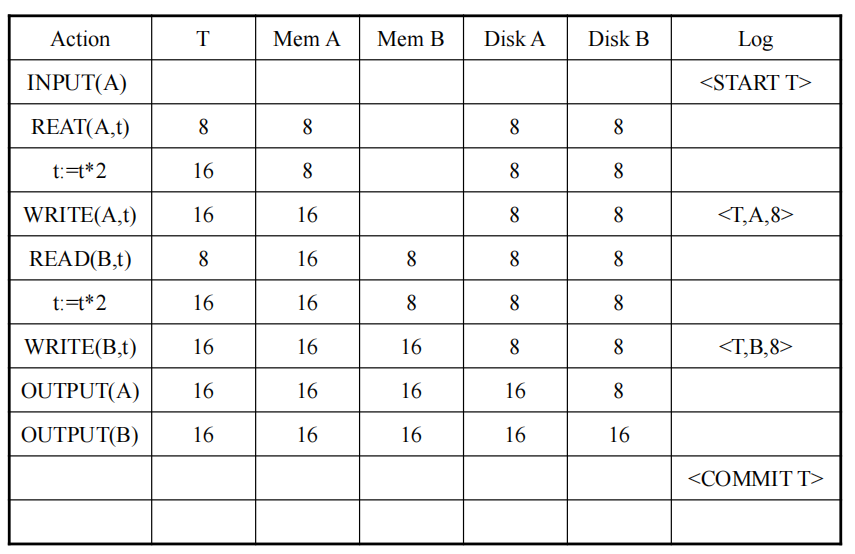
恢复思路
- Step 1: 查看Undo日志,确定每个事务T是否已经完成
<START T>….<COMMIT T>…= yes<START T>….<ABORT T>……= yes<START T>…………………………………= no
- Step 2: 从日志的末尾开始读取记录,对于每一个未提交事务,对它进行Undo操作。
进行反向操作,如对于delete操作,执行对应的insert操作
恢复步骤
- 从日志文件尾部开始读取日志记录
- 若读到
<COMMIT T>: 标记 T 为结束状态 - 若读到
<ABORT T>: 标记 T 为结束状态 - 若读到<T,X,v>:
if T 不是结束状态
then 将 X=v 写入磁盘数据文件
else 忽略该记录 - 若读到
<START T>: 忽略该记录
3.2 基于Redo日志的恢复策略
保证事物的持久性
日志内容
<START T> : 标记事务的开始
<COMMIT T> : T 事务已经提交
<ABORT T> : T 事务已被回滚
<T,X,v> : T 事务已经更新数据项 X, 其新值是 v
日志规则
更新操作和Commit操作:Redo日志文件先写,数据文件后写
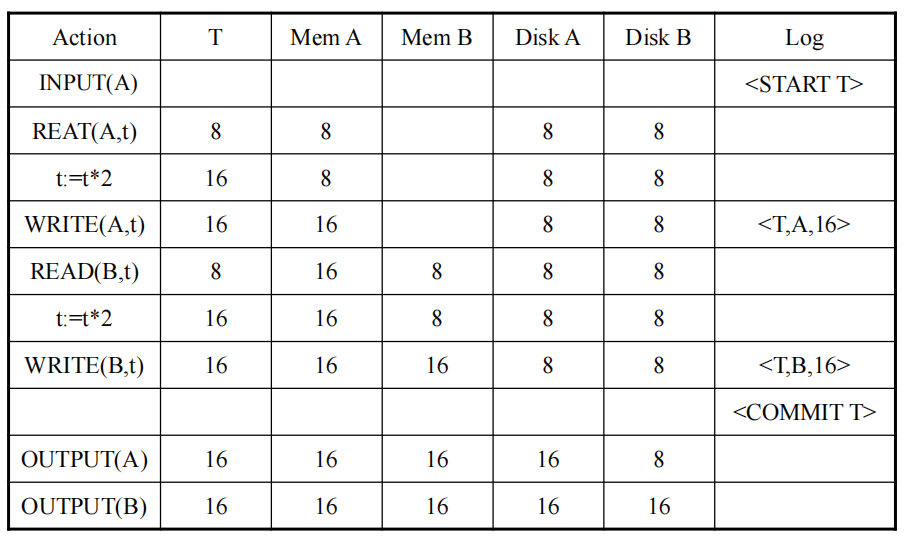
恢复思路
- Step 1: 查看Redo日志,确定每个事务T是否已经完成
<START T>….<COMMIT T>…= yes<START T>….<ABORT T>……= yes<START T>…………………………………= no
- Step 2: 从Redo日志的开头开始读取日志记录,对于每一个已完成的事务,对它进行Redo操作。
3.3 基于Undo/Redo日志的恢复策略
日志内容
<START T> : 标记事务的开始
<COMMIT T> : T 事务已经提交
<ABORT T> : T 事务已被回滚
<T,X,u,v> : T 事务已经更新数据项 X, 其新值是 v,旧值是u
日志规则
更新:日志先写数据后写;Commit则之前、之后皆可
恢复思路
- Step 1: 查看Undo/Redo日志,确定每个事务T是否已经完成
<START T>….<COMMIT T>…= yes<START T>….<ABORT T>……= yes<START T>…………………………………= no
- Step2: 从日志的开头开始读取日志记录,对于每一个已完成的事务,对它进行Redo操作。
- Step3: 从日志的末尾开始读取记录,对于每一个未提交事务,对它进行Undo操作。
(必须先Redo再Undo)
3.4 基于检查点的恢复策略
-
若从头开始进行基于整个日志文件的恢复,会耗费大量时间
-
需要引入基于检查点(check point)的恢复策略
- 在日志文件中增加检查点记录(checkpoint record)
- 增加一个“重新开始文件”,记录日志文件维护情况
- 以最新的检查点作为下次恢复工作的起点
-
检查点记录的内容
- 建立检查点时刻所有正在执行的事务清单
- 这些事务最近一个日志记录的地址
-
重新开始文件的内容
记录各个检查点记录在日志文件中的地址
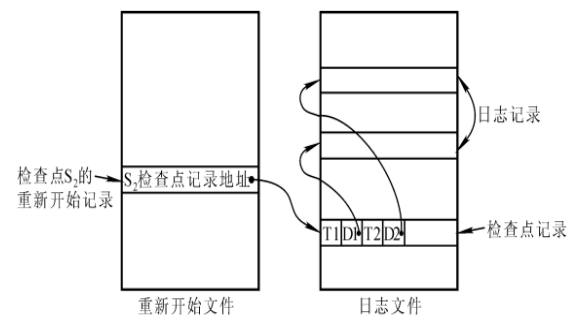
在检查点维护日志文件
- 将当前日志缓冲区中的所有日志记录写入磁盘的日志文件上。
- 在日志文件中写入一个检查点记录。
- 将当前数据缓冲区的所有数据记录写入磁盘的数据库中。
- 把检查点记录在日志文件中的地址写入一个重新开始文件。
建立检查点
按照预定周期,或按照规则条件 (如日志被写满一半)
恢复思路
- 检查点之前提交的事务不需要恢复
- 对于检查点之后才提交的事务,其恢复过程
- 从重新开始文件中找到最后一个检查点记录在日志文件中的地址
- 由该地址在日志文件中找到最后一个检查点记录
- 由该检查点记录得到检查点建立时刻所有正在执行的事务
- 从检查点开始正向扫描日志文件,直到日志文件结束,对读到的事务建立已提交和未提交队列
- 对已提交事务进行Redo操作,对未提交事务进Undo操作
规范化依赖
1 函数依赖
有关函数依赖的几点说明
- 平凡的函数依赖与非平凡的函数依赖
- 当属性集Y是属性集X的子集时,则必然存在着函数依赖X→Y,这种类型的函数依赖称为平凡(Trivial)的函数依赖。 (SNO,CNO)→SNO
- 如果Y不是X的子集,则称X→Y为非平凡的函数依赖。
- 若不特别声明,我们讨论的都是非平凡的函数依赖。
函数依赖的分类
- 完全函数依赖与部分函数依赖
- 设关系模式R(U),U是属性全集,X和Y是U的子集
- 如果
⇸ - 如果对X的某个真子集X′ ,有
- 传递函数依赖
- 设有关系模式R(U),U是属性全集,X,Y,Z是U的子集,
- 若
⇸ - 如果
综上所述,函数依赖分为完全函数依赖、部分函数依赖和传递函数依赖三类,它们是规范化理论的依据和规范化程度的准则
用函数依赖定义候选键
- 设
- 若关系模式R有多个候选键,则选定其中的一个做为主键(Primarykey)。
- 若k是R的一个候选键,并且S⊃K,则称S是R的一个超键 (Super Key)
- 在任一候选键中出现过的属性称为主属性;主属性之外的称为非主属性
用函数依赖定义外键
- 关系模式 R 中属性或属性组 X 并非 R 的候选键,但 X 是另一个关系模式的候选键,则称 X 是R 的外键(Foreign key)
!!! 求解关系的候选解
- 对于关系模式
- L类属性:只在
- R类属性:只在
- LR类属性:在
- N类属性:在
- L类属性:只在
- L类和N类属性必然是候选键中的属性
- R类属性必然不是候选键中的属性
- LR类属性有可能是候选键中的属性
算法
关系模式𝐑 < 𝐔, 𝐅 >,其中𝐔 = {𝑨𝟏, 𝑨𝟐, … , 𝑨𝒏}是R中所有属性的集合
- 求解
根据 - 若
求解属性集 - 若
遍历 - 如果在上一步找到所有的候选键,则算法结束。否则,遍历
2 范式
规范化设计
1NF
- 定义:如果关系模式R,其所有的属性均为简单属性,即每个属性域都是不可再分的,则称R属于第一范式,简称1NF,记作R ∈ 1NF。
2NF
定义
如果关系模式R ∈ 1NF,且每个非主属性都完全函数依赖于R的每个关系键,则称R属于第二范式(Second Normal Form),简称2NF,记作R ∈ 2NF。(去掉非主键的部分依赖)
性质
- 从1NF关系中消除非主属性对关系键的部分函数依赖,则可得到2NF关系。
- 如果R的关系键为单属性,或R的全体属性均为主属性,则R ∈ 2NF。
2NF规范化的形式化描述
设关系模式R(X,Y,Z),R ∈ 1NF,但R不是2NF,其中,X是主属性,Y,Z是非主属性,且存在部分函数依赖,
2NF规范化的过程
SCD(SNO,SN,AGE,DEPT,MN,CNO,SCORE)
- 由SNO→SN,SNO→AGE,SNO→DEPT,(SNO,CNO)⎯ ⎯f → SCORE,可以判断,关系SCD至少描述了两个实体:
- 一个为学生实体,属性有SNO、SN、AGE、DEPT、MN;
- 另一个是学生与课程的联系(选课),属性有SNO、CNO和SCORE。
- 根据投影分解的原则,我们可以将SCD分解成两个关系
- SD(SNO,SN,AGE,DEPT,MN),描述学生实体;
- SC(SNO,CNO,SCORE),描述学生与课程的联系。
- 对于分解后的两个关系SD和SC,主键分别为SNO和(SNO,CNO),非主属性对主键完全函数依赖。因此,SD∈ 2NF,SC ∈ 2NF,而且前面已经讨论,SCD的这种分解没有丢失任何信息,具有无损连接性。
3NF
定义
如果关系模式R ∈ 2NF,且每个非主属性都不传递依赖于R的每个关系键,则称R属于第三范式(Third Normal Form),简称3NF,记作R ∈ 3NF。(去掉非主键的传递依赖)
性质
- 如果R ∈ 3NF,则R也是2NF。
- 如果R ∈ 2NF,则R不一定是3NF。
3NF规范化
把2NF关系模式通过投影分解转换成3NF关系模式的集合。和2NF规范化时遵循的原则相同,即“一事一表”,让一个关系只描述一个实体或者实体间的联系。
例: 将SD(SNO,SN,AGE,DEPT,MN)规范到3NF。
- 分析SD的属性组成,可以判断,关系SD实际上描述了两个实体:
- 一个为学生实体,属性有SNO,SN,AGE,DEPT;
- 另一个是系的实体,其属性DEPT和MN。
- 根据投影分解的原则,我们可以将SD分解成如下两个关系
- S(SNO,SN,AGE,DEPT),描述学生实体;
- D(DEPT,MN),描述系的实体。
- 对于分解后的两个关系S和D,主键分别为SNO和DEPT,不存在非主属性对主键的传递函数依赖。因此,S ∈ 3NF,D ∈ 3NF。
BCNF
定义
如果关系模式R ∈ 1NF,且所有的函数依赖X→Y(Y ∉ X),决定因素X都包含了R的一个候选键,则称R属于BC范式(Boyce-Codd Normal Form),记作R ∈ BCNF。(去掉主键的部分依赖和传递依赖)
BCNF性质
- 满足BCNF的关系将消除任何属性(主属性或非主属性)对键的部分函数依赖和传递函数依赖。也就是说,如果R ∈ BCNF,则R也是3NF。
- 如果R ∈ 3NF,则R不一定是BCNF
BCNF规范化:BCNF规范化是指把3NF关系模式通过投影分解转换成BCNF关系模式的集合。
例 将SNC(SNO,SN,CNO,SCORE)规范到BCNF。
分析SNC数据冗余的原因,是因为在这一个关系中存在两个实体,一个为学生实体,属性有SNO、SN;另一个是选课实体,属性有SNO、CNO和SCORE
根据投影分解的原则,我们可以将SNC分解成如下两个关系:
- S1(SNO,SN),描述学生实体;
- S2(SNO,CNO,SCORE),描述学生与课程的联系。
对于S1,有两个候选键SNO和SN,
对于S2,主键为(SNO,CNO)。
在这两个关系中,无论主属性还是非主属性都不存在对键的部分依赖和传递依赖,S1 ∈ BCNF,S2 ∈ BCNF。
关系模式规范化
步骤
规范化就是对原关系进行投影,消除决定属性不是候选键的任何函数依赖。具体可以分为以下几步:
- 对1NF关系进行投影,消除原关系中非主属性对键的部分函数依赖,将1NF关系转换成若干个2NF关系。
- 对2NF关系进行投影,消除原关系中非主属性对键的传递函数依赖,将2NF关系转换成若干个3NF关系。
- 对3NF关系进行投影,消除原关系中主属性对键的部分函数依赖和传递函数依赖,也就是说使决定因素都包含一个候选键。得到一组BCNF关系。
3 模式分解
最小依赖集构造方法
依据定义分三步对F 进行“极小化处理”,找出F的一个最小依赖集。
- 逐一检查
- 逐一检查
- 逐一取出



模式分解是否正确的判定依据
- 分解具有无损连接性:R与ρ在数据内容方面是否等价
- 分解保持函数依赖:R与ρ在函数依赖方面是否等价
无损连接性分解的判定方法
-
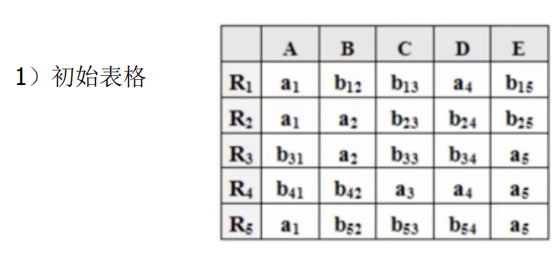
列表法
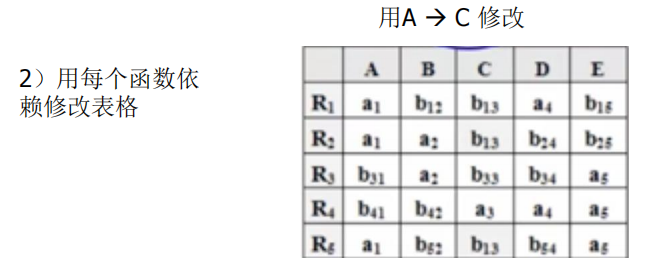
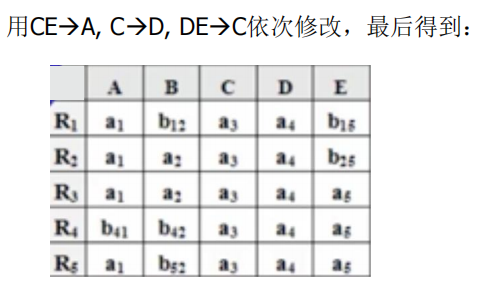
- 构造一个k行n列的二维表T,第i 行对应于一个关系模式Ri,第j列对应于属性Aj,令:tij=aj,若Aj属于Ri;否则tij=bij。
- 对于F中一个FD:X→Y,如果表格中有两行在X分量上相等,在Y分量上不相等,那么把这两行在Y分量上改成相等。如果Y的分量中有一个是aj,那么另一个也改成aj; 如果没有aj,那么用其中的一个bij替换另一个(尽量把ij改成较小的数,亦即取i 值较小的那个)
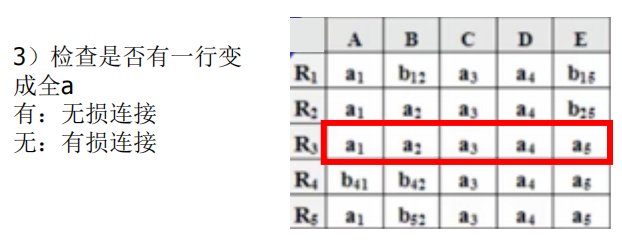
- 若在修改的过程中,发现表格中有一行全是a,即a1 ,a2 ,…,an,那么可立即断定ρ 相对于F 是无损连接分解,此时不必再继续修改。若经过多次修改直到表格不能修改之后,发现表格中不存在有一行全是a的情况,那么分解就是有损的。特别要注意,这里有个循环反复修改的过程,因为一次修改可能导致表格能继续修改。


-
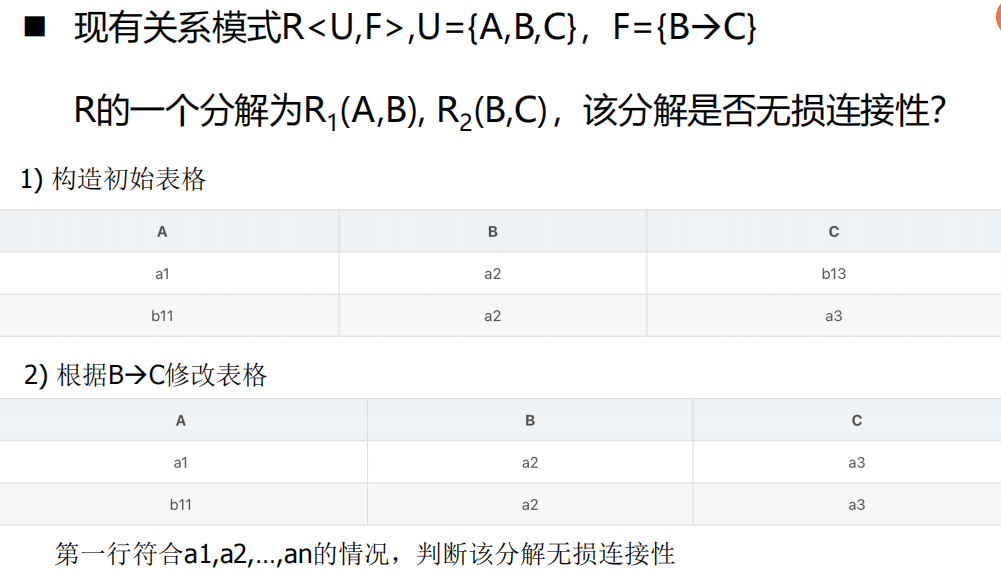
定理法(适合关系模式R分解为两个关系模式R1、R2时)
- 定理:若关系模式
- 示例:已知
,
解: - 设关系模式R 具有函数依赖集F,
, , , ,
- 定理:若关系模式
函数依赖保持性的判定方法






怎样正确的分解到3NF和BCNF
- 分解到BCNF的无损链接分解法

- 分解到3NF的保持依赖分解法


- 分解到3NF的既保持依赖,又无损连接的分解法



数据库设计
概念结构设计
设计E-R图的步骤
1.选择局部应用
- 设计分E-R图首先需要根据系统的具体情况,在多层的数据流图中选择一个适当层次的数据流图,让这组图中每一部分对应一个局部应用,然后以这一层次的数据流图为出发点,设计分E-R图。
- 通常以中层数据流图作为设计分E-R图的依据。原因:
- 高层数据流图只能反映系统的概貌,而低层数据流图过细
- 中层数据流图能较好地反映系统中各局部应用的子系统组成
2.逐一设计分E-R图
- 任务
- 标定局部应用中的实体、属性、码,实体间的联系
- 将各局部应用涉及的数据分别从数据字典中抽取出来,参照数据流图,标定各局部应用中的实体、实体的属性、标识实体的码,确定实体之间的联系及其类型(1:1,1:n,m:n)
- 注意区分实体和属性 (准则参见ER模型一章)
- 步骤
- 以数据字典为出发点定义E-R图。数据字典中的“数据结构”、“数据流”和“数据存储”等已是若干属性的有意义的聚合
- 按上面给出的准则进行必要的调整。
例:设计分E-R图的步骤
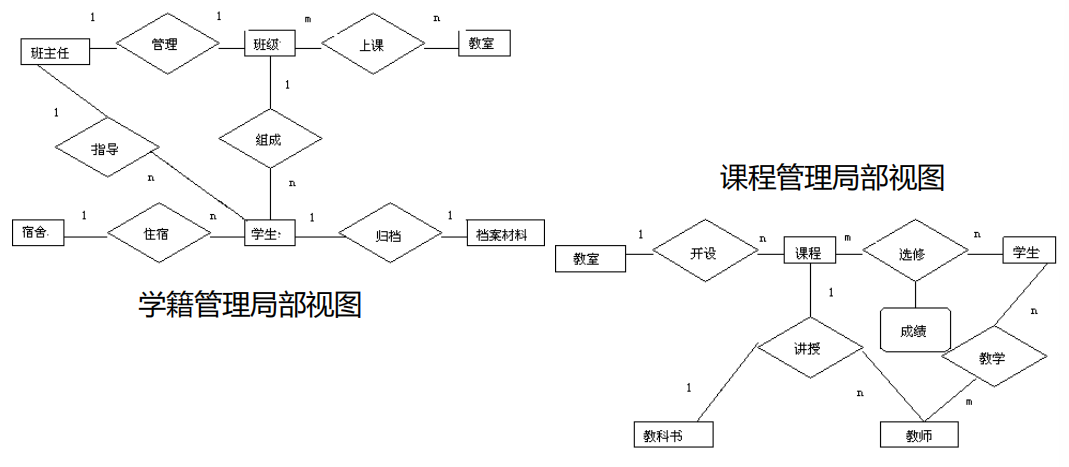
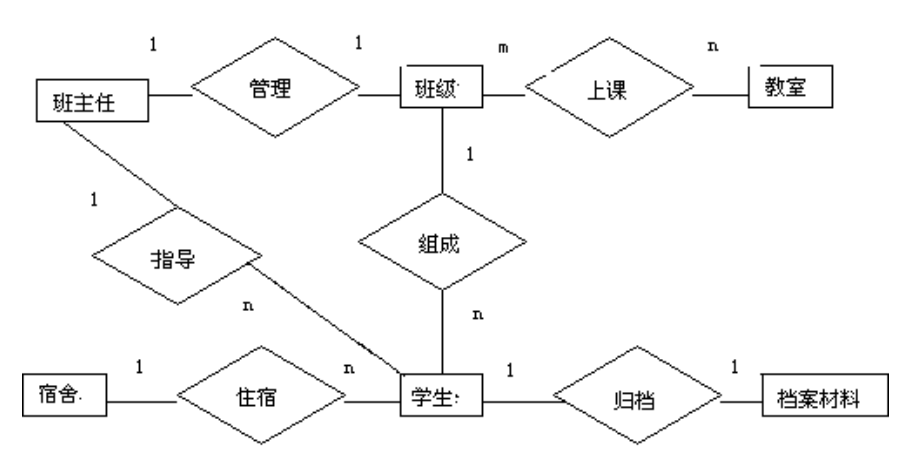
学籍管理局部应用中主要涉及的实体包括学生、宿舍、档案材料、班级、班主任。
实体之间的联系:- 由于一个宿舍可以住多个学生,而一个学生只能住在某一个宿舍中,因此宿舍与学生之间是1:n的联系。
- 由于一个班级往往有若干名学生,而一个学生只能属于一个班级,因此班级与学生之间也是1:n的联系。
- 由于班主任同时还要教课,因此班主任与学生之间存在指导联系,一个班主任要教多名学生,而一个学生只对应一个班主任,因此班主任与学生之间也是1:n的联系。
- 而学生和他自己的档案材料之间,班级与班主任之间都是1:1的联系。
- 最后得到学籍管理局部应用的分E-R图
同样方法可以得到课程管理局部应用的分E-R图
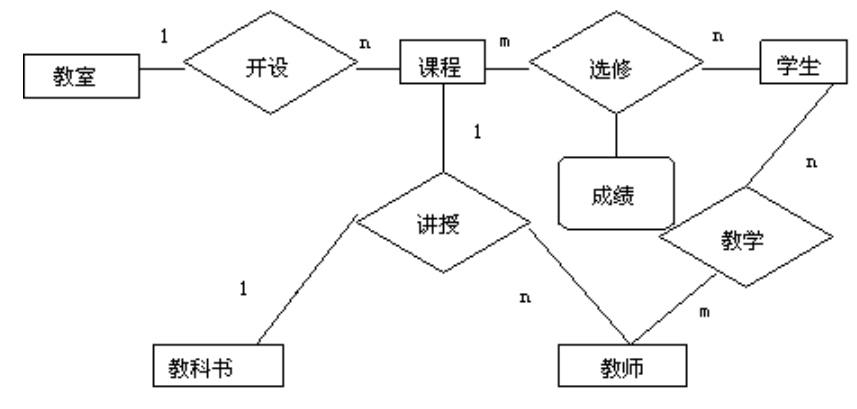
3.集成局部视图,得到全局概念结构
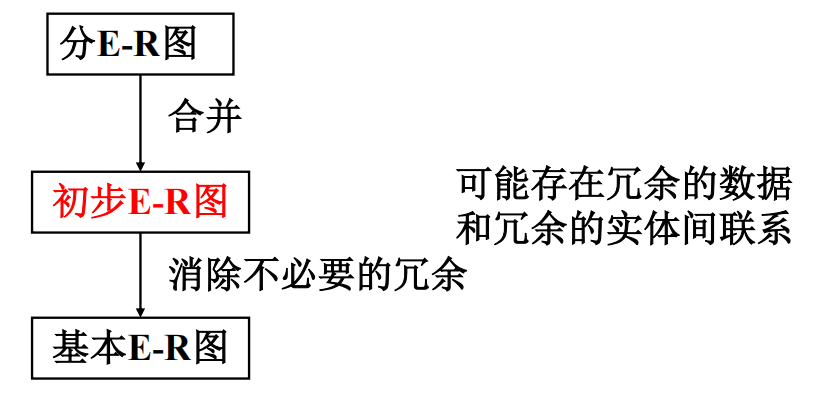
- 各个局部视图即分E-R图建立好后,还需要对它们进行合并,集成为一个整体的数据概念结构即总E-R图。
- 集成的步骤:
- 合并:合理消除各分E-R图的冲突
- 修改与重构
- 在初步ER图基础上,消除不必要的冗余,设计生成基本E-R图
- 消除冗余的方法
-
分析方法
以数据字典和数据流图为依据,根据数据字典中关于数据项之间逻辑关系的说明来消除冗余。
例:教师工资单中包括该教师的基本工资、各种补贴、应扣除的房租水电费以及实发工资。由于实发工资可以由前面各项推算出来,因此可以去掉。 -
规范化理论
函数依赖的概念提供了消除冗余联系的形式化工具- 确定分E-R图实体之间的数据依赖
例:
班级和学生之间一对多的联系:学号→班级号
学生和课程之间多对多的联系:(学号,课程号) →成绩 - 求
逐一考察D中的函数依赖,确定是否是冗余的联系,若是,就把它去掉。
注意:冗余的联系一定在D中,而D中的联系不一定是冗余的,需要根据需求定义加以鉴别
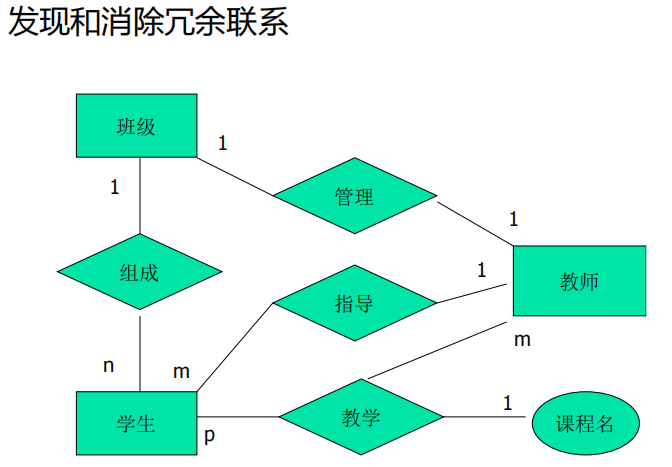
- 找到描述实体间联系的函数依赖集F:
学生->班级; 班级<->教师;
(学生,教师)->课程名; 学生->教师 - 计算F的最小函数依赖集F`:
学生->班级; 班级<->教师;
(学生,教师)->课程名; - F-F`={学生->教师},因此学生与教师的指导联系是冗余联系
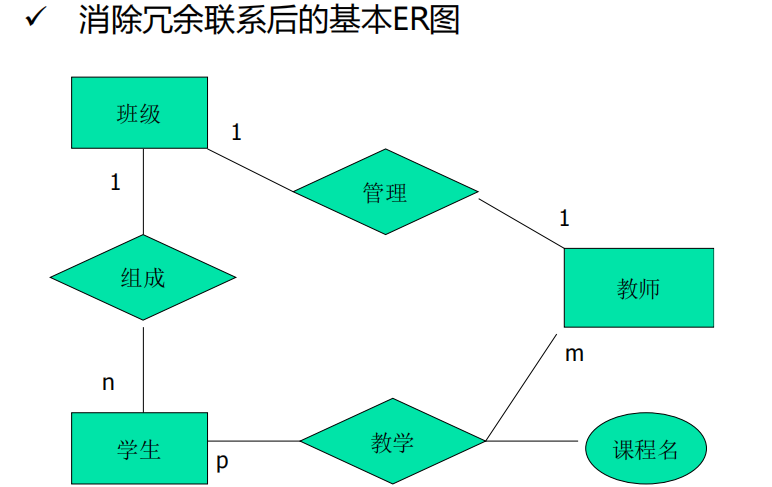
- 确定分E-R图实体之间的数据依赖
-
- 在初步ER图基础上,消除不必要的冗余,设计生成基本E-R图
- 数据模型的优化
按照数据依赖的理论对关系模式逐一进行分析,考查是否存在部分函数依赖、传递函数依赖、多值依赖等,确定各关系模式分别属于第几范式。 - 按照需求分析阶段得到的各种应用对数据处理的要求,分析对于这样的应用环境这些模式是否合适,确定是否要对它们进行合并或分解(是否需要用到非规范化设计手段?)。
- 整体概念结构最终还应该提交给用户,征求用户和有关人员的意见,进行评审、修改和优化,然后把它确定下来,作为数据库的概念结构,作为进一步设计数据库的依据
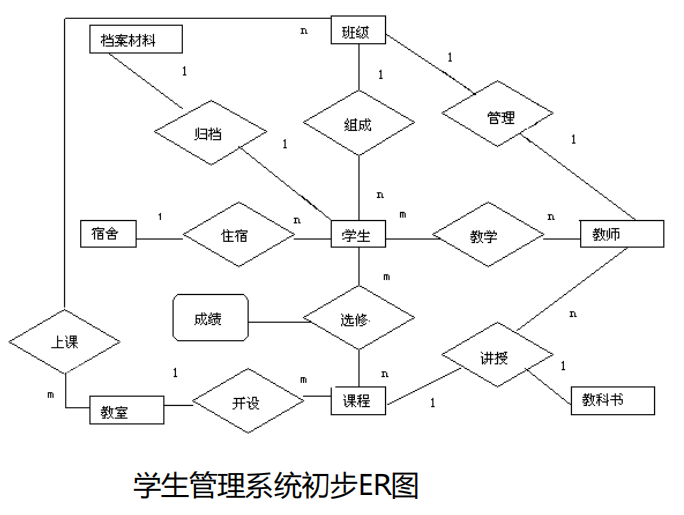
例:合并分E-R图,生成初步E-R图
合并前例:学籍管理局部视图, 课程管理局部视图
合并后获得学生管理系统初步ER图