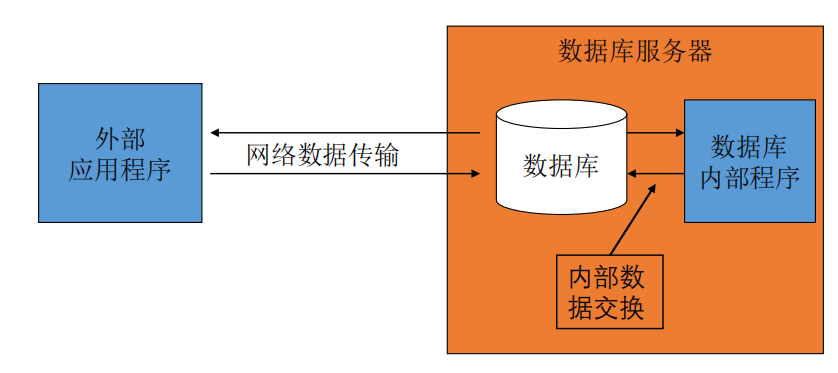
- sql语言不好使,所以对数据的分析处理主要由数据库应用程序来完成
- 数据库应用程序的两种形式:
- 数据库内部应用程序
- 数据库外部应用程序
1 数据库内部编程
数据库内部程序的常见形式:
- 存储过程
- 函数
- 触发器
1.1 存储过程
- 存储过程
- 由过程化SQL语句书写的过程,经编译和优化后存储在数据库服务器中,使用时只要调用即可。
- 通常将多次重复执行的代码段编写成一个过程(procedure orfunction),保存在数据库中
- 存储过程的优点
- 是SQL和模块化编程的结合,能够完成复杂业务功能
- 在创建的时候进行预编译,可以提高SQL执行效率
- 位于数据库服务器上,调用的时候无需通过网络传输大量数据
- 可以做为一种安全机制来加以充分利用。例如参数化的存储过程可以防止SQL注入式的攻击
使用
创建
CREATE PROCEDURE procedure_name (
[ IN | OUT | INOUT ] param_name type [ ,... ]
)
[ BEGIN ]
sql_statement
[ END ]
procedure_name:数据库服务器合法的对象标识param_name:用名字来标识调用时给出的参数值,必须指定值的数据类型。参数也可以定义输入参数、输出参数或输入/输出参数。默认为输入参数。sql_statement:是一个过程化SQL块。包括声明部分和可执行语句部分
删除
DROP PROCEDURE prodedure_name
调用
CALL procedure_name (param_name type [ ,... ])
- 使用CALL方式激活存储过程的执行;
- 数据库服务器支持在过程体中调用其他存储过程
语法
变量
流程控制
常用数据库函数与命令
嵌入式SQL
# 下面代码能将stuid=001的学生的cno=55的课程的score++
declare v_score int;
select score into v_score from sc where cno=55 and stuid=001; # into v_score
Set v_score=v_score+1;
Update sc set score=v_score where cno=55 and stuid=001; # score=v_score
动态SQL
- 根据用户输入参数和/或数据库状态,动态确定程序中的SQL语句内容
Prepare:组装SQL语句Exceute:动态执行SQL语句
CREATE PROCEDURE count_field(IN FIELDNAME VARCHAR(255), IN FIELDVALUE INT)
BEGIN
SET @sql = CONCAT('SELECT COUNT(*) FROM stu WHERE ‘, FIELDNAME, ' = ?’);
PREPARE stmt FROM @sql;
SET @fieldvalue = FIELDVALUE;
EXECUTE stmt USING @fieldvalue;
DEALLOCATE PREPARE stmt;
END;
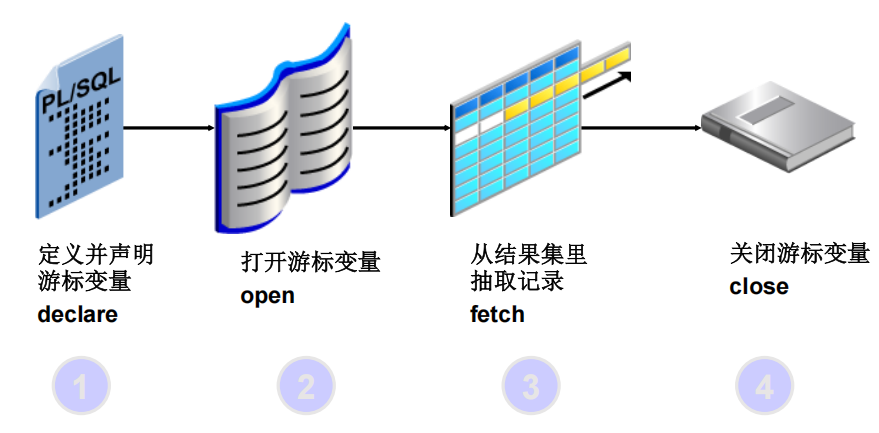
游标编程
- SQL语句以关系为操作对象和操作结果,例如由 SELECT 语句返回的行集包括满足该语句的 WHERE 子句中条件的所有行。应用程序有时需要遍历关系表,对每行数据进行单独处理。SQL语言不能实现这样的操作要求。
- 应用程序需要一种机制以便每次处理一行或一部分行。游标就是提供这种机制的对SELECT查询结果集的一种扩展
- 游标可以对查询语句返回的行结果集中的每一行进行操作。
主要功能包括:- 定位到结果集中的指定行
- 从结果集的当前位置检索一行或多行
- 可对结果集中当前位置的行进行数据修改
- 可以显示其它用户对结果集中的数据库数据进行的数据更改
CREATE PROCEDURE stu_count(c_age int)
BEGIN
DECLARE p_age int; # 声明变量
DECLARE p_c int; # 声明游标结束判断变量,默认值为0;
DECLARE fetchSeqOk boolean DEFAULT 0;
DECLARE my_cursor CURSOR for select age FROM t_user; -- 定义游标
DECLARE CONTINUE HANDLER FOR NOT FOUND SET fetchSeqOk = 1;
-- 游标执行结束时将会设置fetchSeqOk 变量为1
-- 在MySql中,造成游标溢出时会引发mysql预定义的NOT FOUND错误
SET p_c=0;
OPEN my_cursor; # 打开游标
WHILE fetchSeqOk=0 DO. -- 判断是不是到了最后一条数据
fetch my_cursor into p_age; -- 游标改变位置指向下一行,取下一行数据
IF p_age<c_age THEN
SET p_c=p_c+1;
END IF;
END WHILE;
Select p_c as concat(’小于’, c_age, ’岁的总人数’); -- 输出结果
CLOSE my_cursor; -- 关闭游标,释放内存
END
1.2 自定义函数
需求:
输入:字符串
输出:第一个字母大写,后面的字母小写
实现:
CREATE FUNCTION capitalize(input_string VARCHAR(255))
RETURNS VARCHAR(255)
BEGIN
DECLARE output_string VARCHAR(255);
SET output_string =
CONCAT(UPPER(LEFT(input_string,1)),LOWER(SUBSTRING(input_string, 2)));
RETURN output_string;
END
使用:
select capitalize(’samPLeSTring’);
select capitalize(stu_name) from stu;
2 数据库应用系统开发
2.1 数据库访问与Python MySQL Client
2.1.1 数据库访问
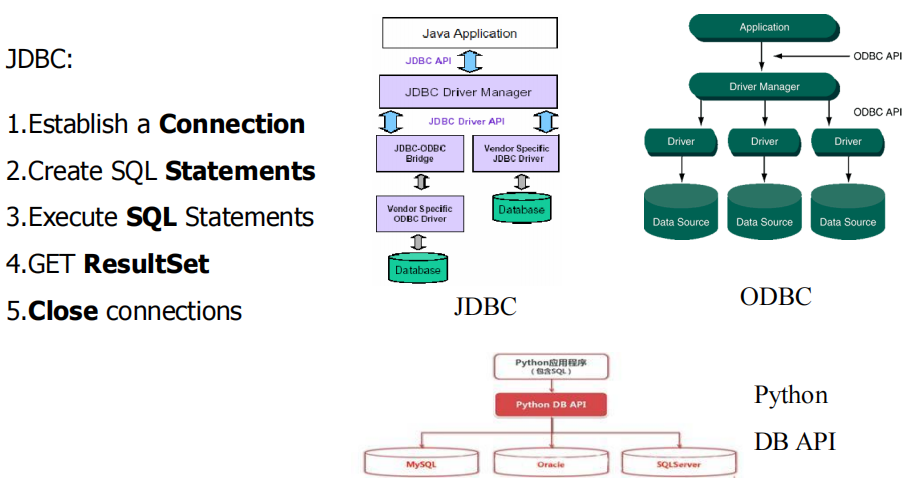
- 各种高级编程语言都提供访问和操作数据库的类库
- 使用类库进行数据库开发的基本过程:
import java.sql.*;
class Test {
public static void main(String[] args) {
try {
Class.forName("sun.jdbc.odbc.JdbcOdbcDriver"); //dynamic loading of driver
String filename = "c:/db1.mdb"; //Location of an Access database
String database = "jdbc:odbc:Driver={Microsoft Access Driver (*.mdb)};DBQ=";
database+= filename.trim() + ";DriverID=22;READONLY=true}"; //add on to end
Connection con = DriverManager.getConnection( database ,"","");
Statement s = con.createStatement();
s.execute("create table TEST12345 ( firstcolumn integer )");
s.execute("insert into TEST12345 values(1)");
s.execute("select firstcolumn from TEST12345");
ResultSet rs = s.getResultSet();
if (rs != null) // if rs == null, then there is no ResultSet to view
while ( rs.next() ){ // this will step through our data row-by-row
/* the next line will get the first column in our current row's ResultSet
as a String ( getString( columnNumber) ) and output it to the screen */
System.out.println("Data from column_name: " + rs.getString(1) );
}
s.close(); // close Statement to let the database know we're done with it
con.close(); //close connection
}catch (Exception err) {
System.out.println("ERROR: " + err);
}
}
}
2.2.2 Python MySQL Client
- PyMySQL 是在 Python3.x 版本中用于连接 MySQL 服务器的一个库,Python2 中则使用 mysqldb。
- PyMySQL 遵循 Python 数据库 API v2.0 规范,并包含了 pure-Python MySQL 客户端库。
- PyMySQL安装:
pip install PyMySQL
例1:数据库连接
- 连接数据库前,请先确认以下事项
- 在本地或者云数据库已经创建了数据库 TESTDB.
- 记得自己数据库的用户名和密码
- Python环境已经安装了PyMySQL库
- 下面我们以TESTDB数据库为示例演示数据库的连接、建表、插入、查询、更新、删除等方法。
新建一个python文件,写入如下内容

执行以上代码输出结果如下(具体版本可能会有所不同):

例2:创建表
如果数据库连接存在我们可以使用 execute() 方法来为数据库创建表,如下所示创建表EMPLOYEE:

执行以上代码,发现数据库表已经创建好:
例3:插入数据
以下实例使用执行 SQL INSERT 语句向表 EMPLOYEE 插入记录:
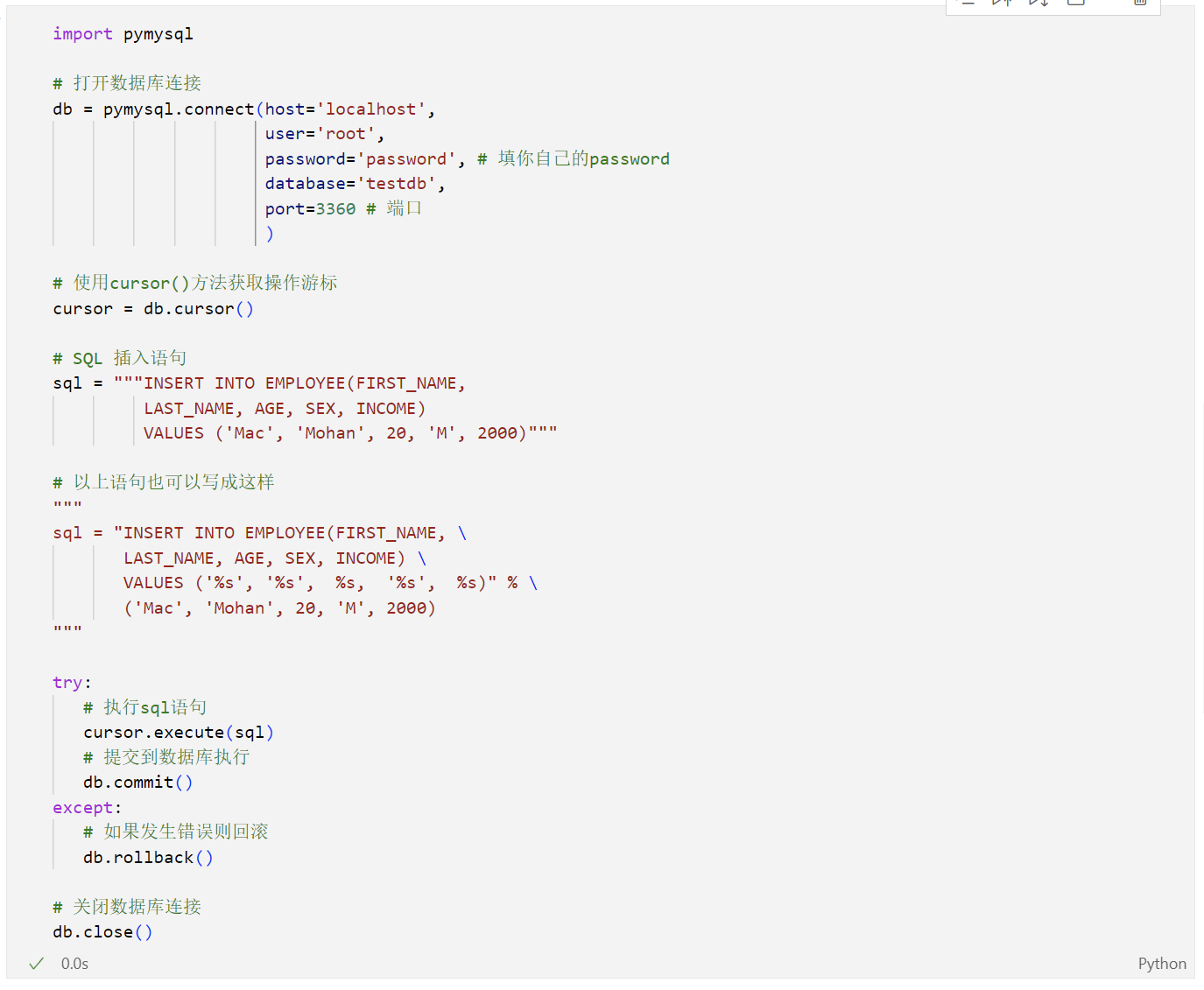
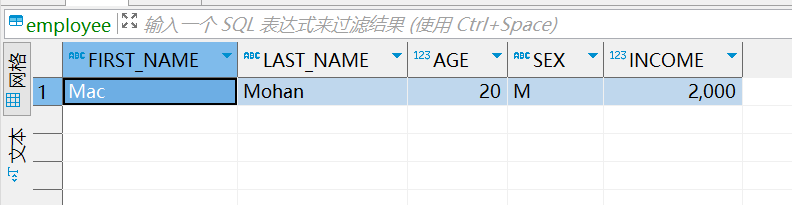
执行以上代码,发现数据已经插入到表中:
例4:查询操作
Python查询Mysql使用 fetchone() 方法获取单条数据, 使用 fetchall() 方法获取多条数据。
fetchone(): 该方法获取下一个查询结果集。结果集是一个对象;fetchall(): 接收全部的返回结果行;rowcount: 这是一个只读属性,并返回执行execute()方法后影响的行数。
查询EMPLOYEE表中salary(工资)字段大于1000的所有数据
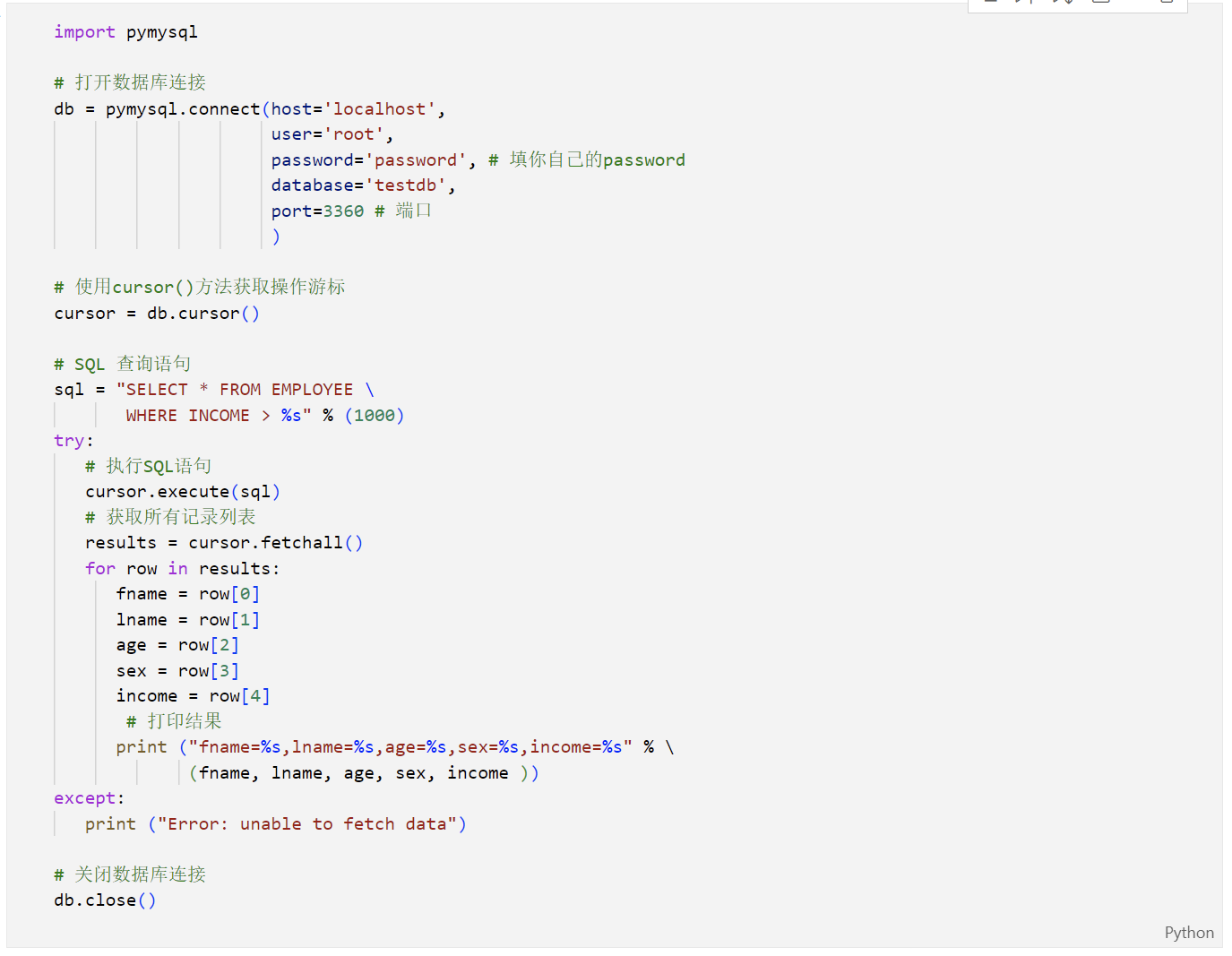
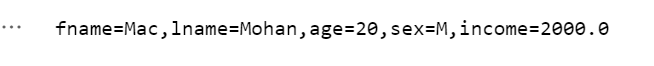
例5:更新操作
更新操作用于更新数据表的数据,以下实例将 TESTDB 表中 SEX 为 'M' 的 AGE 字段递增 1:

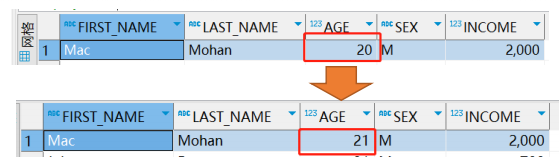
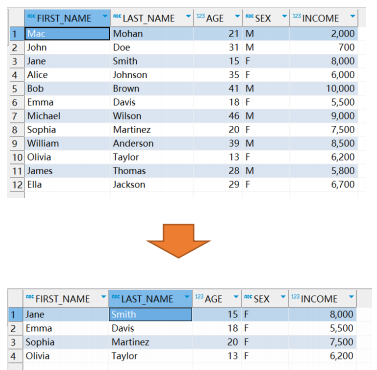
例6:删除操作
删除操作用于删除数据表中的数据,以下实例演示了删除数据表 EMPLOYEE 中AGE 大于 20 的所有数据:

事务机制——保证数据的一致性
- 事务机制可以确保数据一致性。事务应该具有4个属性:原子性、一致性、隔离性、持久性。这四个属性通常称为ACID特性。
- 原子性(atomicity)。一个事务是一个不可分割的工作单位,事务中包括的诸操作要么都做,要么都不做。
- 一致性(consistency)。事务必须使数据库从一个一致的状态转换到另一个一致的状态。通过使用
commit和rollback,可以确保数据库始终处于一致的状态。 - 隔离性(isolation)。一个事务的执行不能被其他事务干扰。即一个事务内部的操作及使用的数据对并发的其他事务是隔离的,并发执行的各个事务之间不能互相干扰。
- 持久性(durability)。持续性也称永久性(permanence),指一个事务一旦提交,它对数据库中数据的改变就应该是永久性的。接下来的其他操作或故障不应该对其有任何影响
- Python DB API 2.0 的事务提供了两个方法
commit或rollback。 - 对于支持事务的数据库, 在Python数据库编程中,当游标建立之时,就自动开始了一个隐形的数据库事务。
commit()方法提交当前事务,使得所有更改成为永久性的。rollback()方法回滚当前事务,撤销自上次提交以来的所有更改。- 每一个方法都开始了一个新的事务。
错误处理
CREATE PROCEDURE delete_table_proc ( IN table_name VARCHAR(100) )
-- 创建一个名为 delete_table_proc 的存储过程,接受一个参数 table_name,表示要删除的表名
BEGIN
DECLARE error_msg VARCHAR(255) DEFAULT NULL;
-- 声明一个变量 error_msg,用于存储错误信息,初始值为 NULL
START TRANSACTION;
-- 开始一个新的事务,确保后续操作的原子性
BEGIN
SET @sql_statement = CONCAT('DROP TABLE ', table_name);
-- 构造一个 SQL 语句,用于删除指定的表
PREPARE stmt FROM @sql_statement;
-- 预编译 SQL 语句
EXECUTE stmt;
-- 执行预编译的 SQL 语句,即删除表
DEALLOCATE PREPARE stmt;
-- 释放预编译的 SQL 语句资源
EXCEPTION
WHEN others THEN
-- 当发生任何异常时,执行以下操作
SET error_msg = CONCAT('Error deleting table ', table_name, ': ', GET_DIAGNOSTICS CONDITION 1);
-- 设置错误信息,包括表名和具体的错误诊断信息
ROLLBACK;
-- 回滚事务,撤销所有未提交的更改
END;
IF error_msg IS NULL THEN # 如果 error_msg 为 NULL,表示没有发生错误
COMMIT; -- 提交事务,使删除操作生效
SELECT 'Table deleted successfully.' AS message; -- 返回成功消息
ELSE -- 如果 error_msg 不为 NULL,表示发生了错误
SELECT error_msg AS message; -- 返回错误信息
END IF; -- 结束条件判断
END -- 结束存储过程
2.2 对象关系映射--ORM
2.2.1 简介
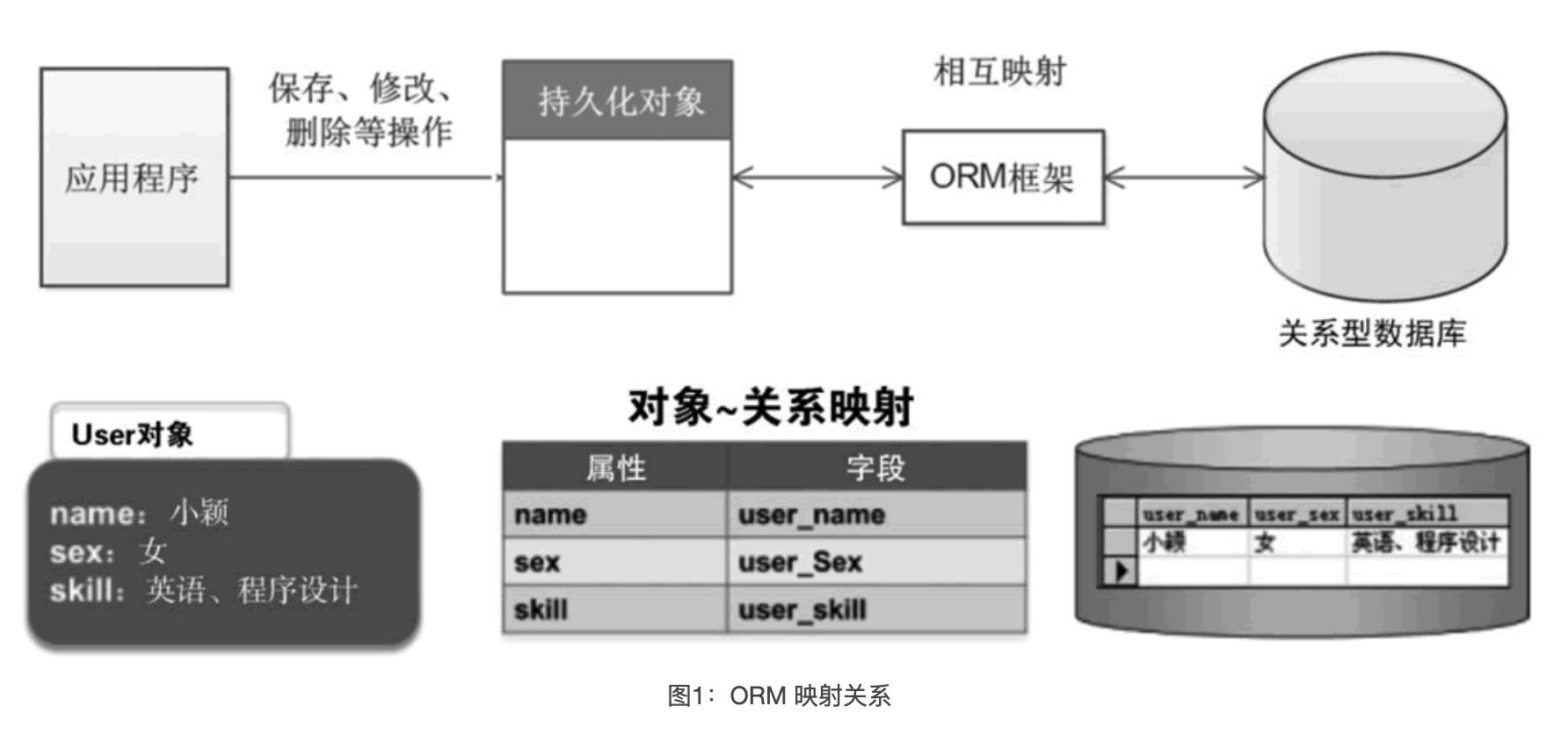
大多数系统在数据管理方面采用关系数据库,同时使用面向对象的语言来开发上层应用。然而,在进行数据存取时,必须在对象与二维表之间建立映射关系,这意味着对象数据需要被扁平化为关系表格式后才能存储。由于关系模型的建模能力有限,面向对象的方法无法完全贯彻到关系数据库中。此外,应用程序需要嵌入SQL语言才能操纵数据库。这些不便之处被称为"Impedance mismatch",即阻抗失配,反映了对象模型与关系模型之间的不匹配问题。
- 为什么用ORM
因为将对象映射到表会遇到很大困难,特别是对象含有复杂结构/存在大的非结构化的对象/存在类继承。
映射的结果很可能是:表存取的效率很差;或在表中检索对象很困难 - OR映射
- 用户开发和维护一个中间件层,负责将对象数据映射到关系数据库的表中
- 系统中其它模块可以通过OR映射层以操作对象的方法操作关系表中的数据
- OR映射对前端开发人员屏蔽了数据库底层细节,使得他们可以专注于业务流程的实现,极大提高了应用系统开发的生产率
2.2.2 Active record
-
Active record:一个对象既包含数据又包含行为。这些数据大部分是持久性的,需要存储在数据库中。Active Record使用最明显的方法,将数据访问逻辑放在域对象中。这样,所有人都知道如何在数据库中读取和写入数据。”
-
将对象和数据库表看作是一一对应的关系,一个对象对应一个数据库表中的一行数据,对象和行数据之间的映射关系由ORM框架自动维护。通过对象的属性来操作数据表,例如修改对象的属性后,直接通过ORM框架更新到数据库表中。
-
优点:简单,容易理解
-
缺点:耦合度高,性能较差
-
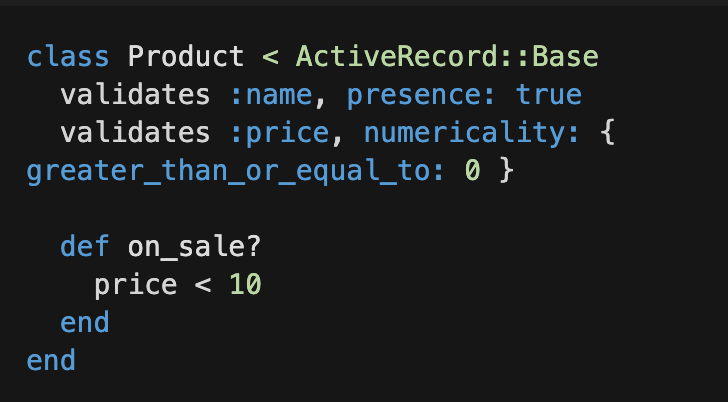
在下面的示例中,我们定义了一个 "Product" 类,该类使用"ActiveRecord::Base" 派生自 ActiveRecord 模型的基类。我们还定义了两个验证,以确保在创建和更新产品时,“name” 字段不为空,而 “price” 字段为数字且大于或等于零。除此之外,我们还定义了一个简单的辅助方法“on_sale?”,该方法检查产品价格是否低于 10 美元。
-
当我们将此类链接到与数据库中的 “products” 表的记录时,Active Record 将处理将数据映射到对象属性,并提供了 CRUD(创建,读取,更新和删除)操作,使我们能够轻松与底层数据库进行交互。例如,我们可以使用以下方式创建新产品:

-
在上面的例子中,我们创建了一个新的 "Product" 对象,并将其"name" 属性设置为 "New product", "price" 属性设置为 5。然后,我们通过 “save” 方法存储新的产品记录。这将在数据库中插入新的“products” 表记录,以及更新相应的 Product 对象。
2.2.3 Data Mapper
- Data Mapper:将对象和数据库表看作是两个独立的概念,对象类与数据库表之间没有必然的联系,需要手动定义对象属性和数据表的字段之间的映射关系。对象的读写操作不直接与数据库交互,而是通过数据访问对象(Data Access Object,DAO)来实现。
- 优点:
- 提供更好的灵活性,选择需要的对象属性进行存储
- 使得应用层和数据层相对独立,隐藏了彼此的细节
- 性能较好
- 缺点:
- 复杂,需要一定的学习成本,部署较为困难
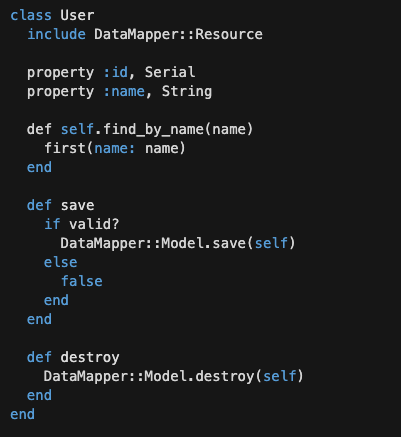
例
在右边的例子中,定义了一个“User” 类,它是 DataMapper::Resource 的子类。使用了 DataMappper 的 DSL(领域特定语言)来定义对象和数据表之间的映射关系
- 例如,使用 “property” 方法定义了 “id” 和 “name” 属性,并指定它们所需的数据类型。
- 此外还定义了几个方法,以便处理User 记录的 CRUD 操作。
- find_by_name:该方法通过 DataMapper 的 “first” 方法从数据库中检索符合条件的第一条记录。
- save和destroy方法:它们分别将对象的更改保存到数据库中或删除其对应的记录
2.2.4 总结
- 优点
- 提高开发效率
- 数据库平台透明
- 数据库结构自动维护
- 代码可读性高
- 缺点
- 需要一定的学习成本
- 性能问题
- 不适用于复杂场景
