假定:
- 源语言:通用的过程语言(函数式语言,如 C,Pascal,FORTRAN)
- 生成代码:栈式抽象机的(伪)汇编程序
- 翻译方法:自顶向下的属性翻译
- 语法成分翻译子程序参数设置:
- 继承属性为值形参
- 综合属性为变量形参
- 语法成分翻译动作子程序参数设置:(如动作
- 继承属性为值形参
- 综合属性不设形参,而作为动作子程序的返回值
(由RETURN语句返回)
1 语义分析的概念
- 上下文有关分析:即标识符的作用域(使用变量时要检查是否声明过)
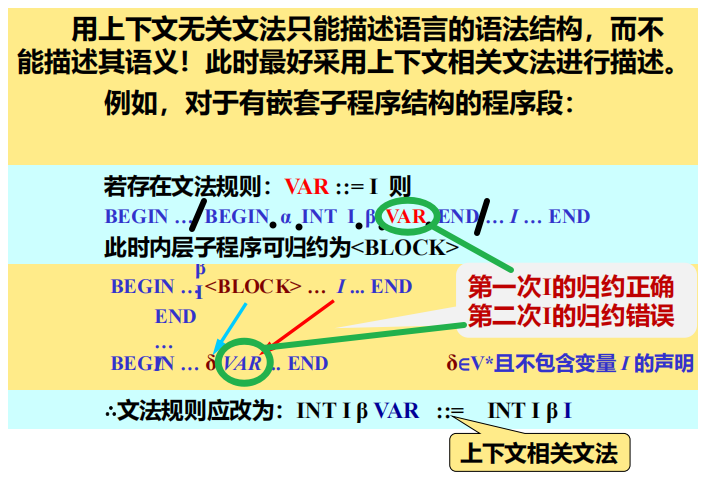
- 上下文有关文法构造困难且不好使 => 使用上下文无关文法+符号表
- 把与语义相关的上下文有关信息填入符号表中,并通过查符号表中的这些信息来分析程序的语义是否正确。
- 类型的一致性检查
- 语义处理:
- 声明语句:其语义是声明变量的类型等,并不要求做其他的操作。
语义分析程序的工作是填符号表,登录名字的特征信息,分配存储。 - 执行语句:语义是要做某种操作。
语义处理的任务:按某种操作的目标结构生成中间代码或目标代码。
- 声明语句:其语义是声明变量的类型等,并不要求做其他的操作。
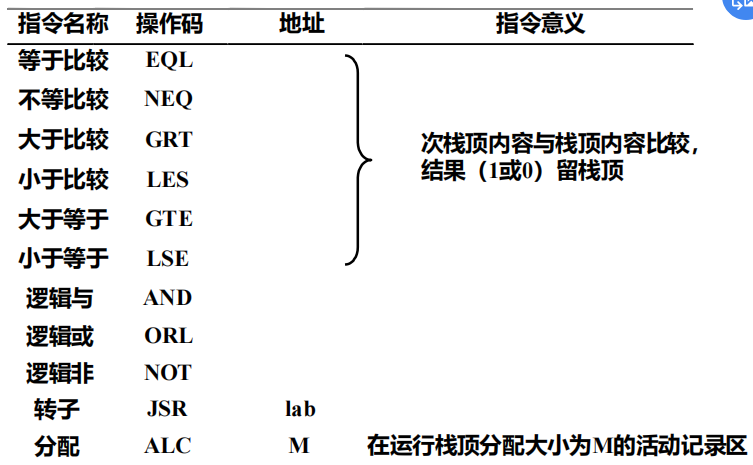
2 栈式抽象机及其汇编指令
- 栈式抽象机
- 三个存储器
- 数据存储器 (存放AR的运行栈)
- 操作存储器 (操作数栈)
- 指令存储器
- 一个指令寄存器
- 多个地址寄存器组成。
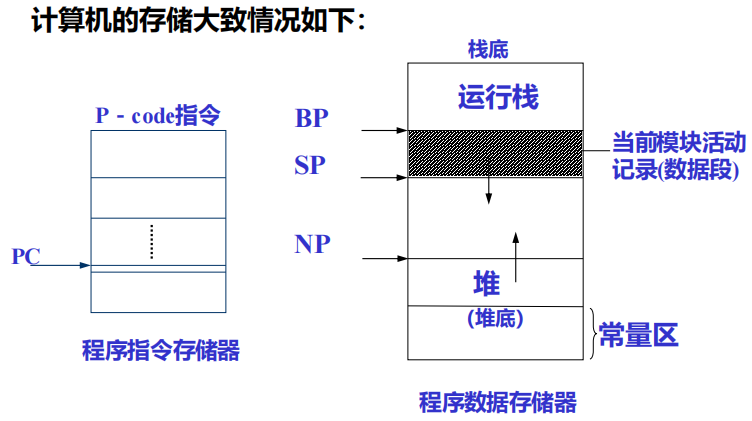

- 三个存储器
3 声明的处理
-
语义的表示:
给出语言结构的属性翻译文法来说明其语义及语义动作,并把这些语义动作插入属性翻译文法产生式中的适当位置。 -
编译程序的任务:
- 编译程序处理声明语句要完成的主要任务为:
填表工作(填表前先得查表,检查是否重名)。- 分离出每一个被声明的实体,并把它们的名字填入符号表中
- 把被声明实体的有关特性信息尽可能多地填入符号表中
- 对于已声明的实体,在处理对该实体的引用时要做的事情:
查表工作- 检查对所声明的实体引用(种类、类型等)是否正确
- 根据实体的特征信息,例如类型、所分配的目标代码地址(可能为数据区单元地址,或目标程序入口地址)生成相应的目标代码
- 编译程序处理声明语句要完成的主要任务为:
-
声明有常量声明,变量(包括简单变量,数组变量和记录变量等)和过程(函数)声明等,这里主要讨论常量声明和简单变量、数组声明的处理。
-
声明的两种方式:
- 类型说明符放在变量的前面。如C语言: int a; 在填表时已知类型和a的值(名字),直接填入符号表。
- 类型说明符放在变量的后面。如:Pascal,PL/1,Ada等,需要反填。
如PL/1声明语句:DECLARE( X, Y(N), YTOTAL) FLOAT;



3.1 常量类型声明处理
常量标识符通常被看作是全局名。


3.2 简单变量声明处理


- 对于变长字符串(或其它大小可变的数据实体),往往需要采用动态申请存储空间的办法把可变长实体存储在堆中。
- 我们可通过指向存放该实体数据区的指针来引用该实体,有时还应得到该实体存储空间的大小信息,并一起填入符号表内。
- 即可变长实体存储在堆中,而其指针存放在符号表中。
3.3 数组变量声明的处理
-
对于静态数组,即数组的大小在编译时是已知的,编译程序在处理数组声明时,可建立一个数组模板(又称为数组信息向量),以便以后的程序中引用该数组元素时,可按照该模板提供的信息,计算数组元素(下标变量)的存储地址。
-
对于动态数组,其大小只有在运行时才能最后确定。我们在编译时仅为该模板分配一个空间,而模板本身的内容将在运行时才能填入。
-
大部分程序设计语言,数组元素是按行(优先)存放在存储器中的(FORTRAN 例外!它按列(优先)存放数组元素)
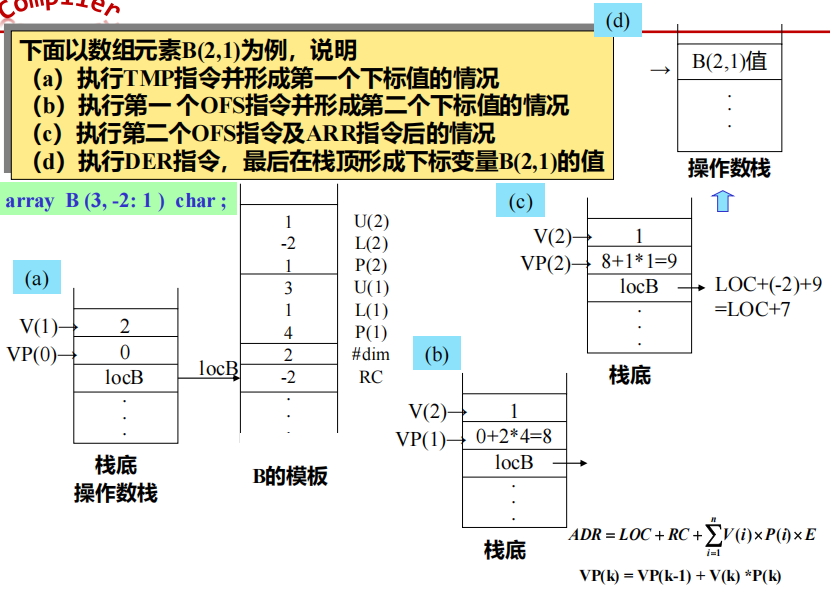
如声明数组 array B(N, -2:1) char ;
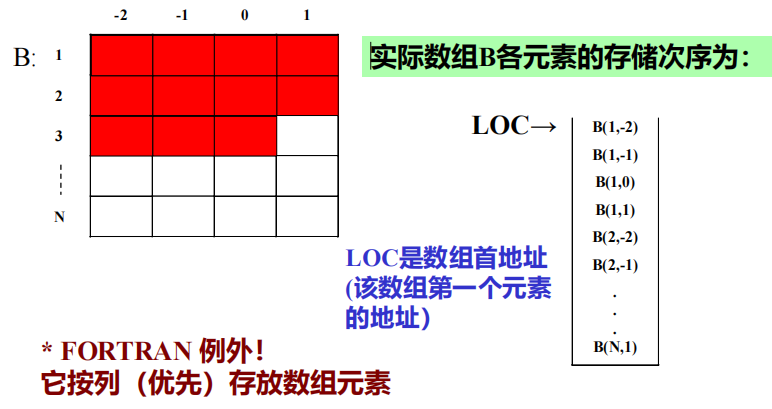
1 n维数组的地址计算公式

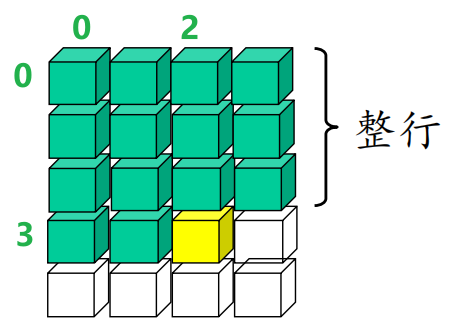
V(1) = 3, U(1) = 4, L(1) = 0
V(2) = 2, U(2) = 3, L(2) = 0
P(1) = U(2)-L(2)+1 = 4
P(2) = 1
ADR = LOC + (3*P(1) + 2*P(2)) * E = LOC + 14E
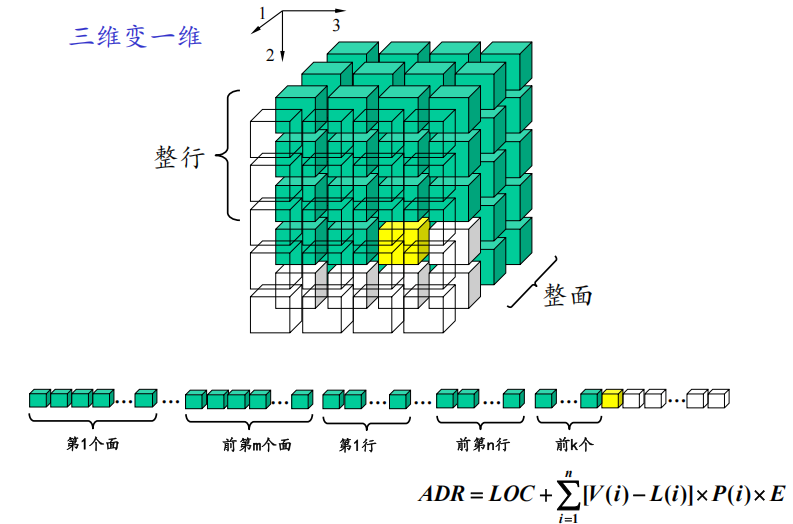
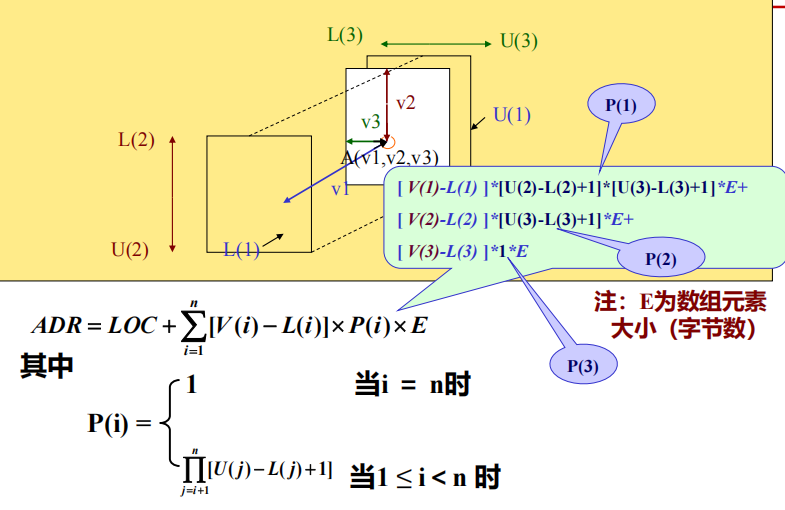
1* 计算公式改进——提取出来不变的部分(RC)

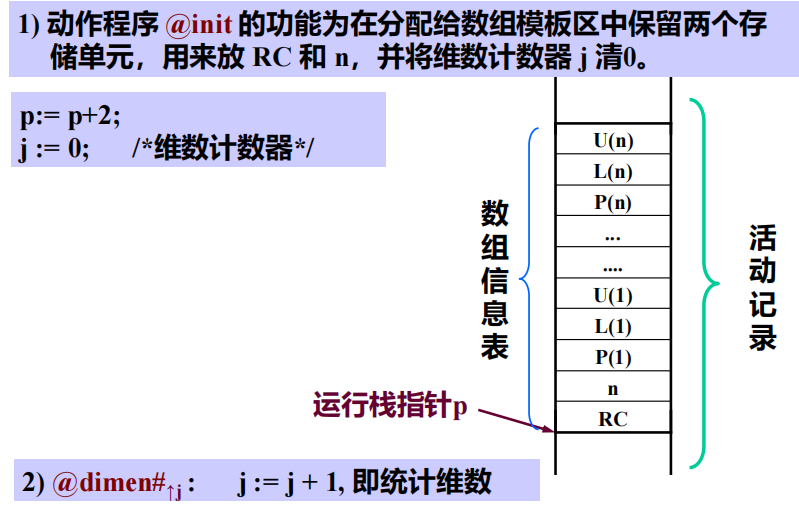
2 数组信息向量表(模板)
功能:
- 用于计算下标变量地址
- 检查下标是否越界
 例子
例子
3 数组声明的 ATG 文法



4 表达式的处理
- 分析表达式的主要目的是生成计算该表达式值的代码。通常的做法是把表达式中的操作数装载(LOAD)到操作数栈(或运行栈)栈顶单元或某个寄存器中,然后执行表达式所指定的操作,而操作的结果保留在栈顶或寄存器中。
- 注:操作数栈即操作栈,它可以和前述的运行栈(动态存储分配)合而为一,也可单独设栈。
本章中所指的操作数栈实际应与动态运行(存储分配)栈分开。
例:整形表达式

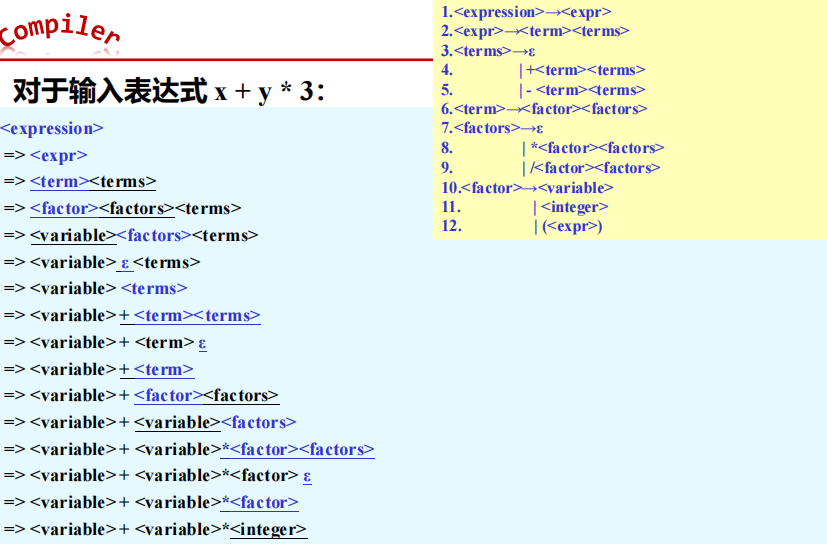

- 上面所述的表达式处理实际上忽略了出现在表达式中各操作数类型的不同,且变量也仅限于简单变量。
- 下面假定表达式中允许整型和实型混合运算,并允许在表达式中出现下标变量(数组元素)。因此应该增加有关类型一致性检查和类型转换的语义动作,也要相应产生计算下标变量地址和取下标变量值的有关指令。
例:整型+实型+数组表达式
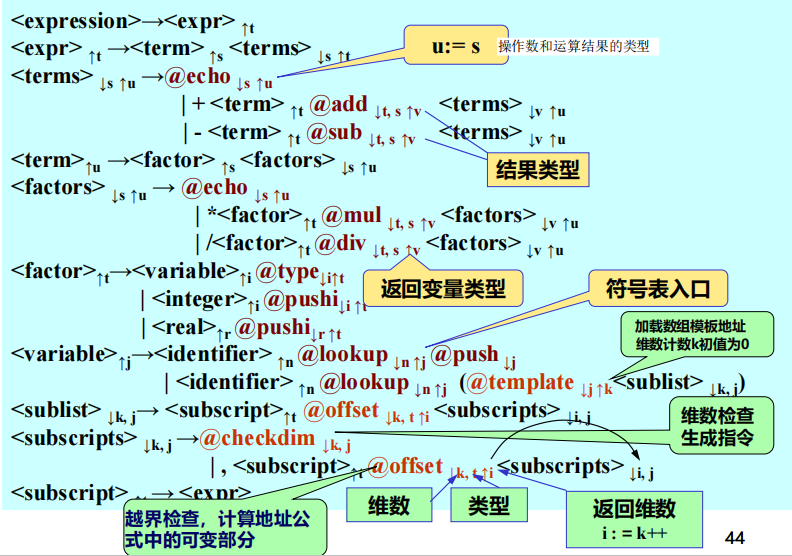
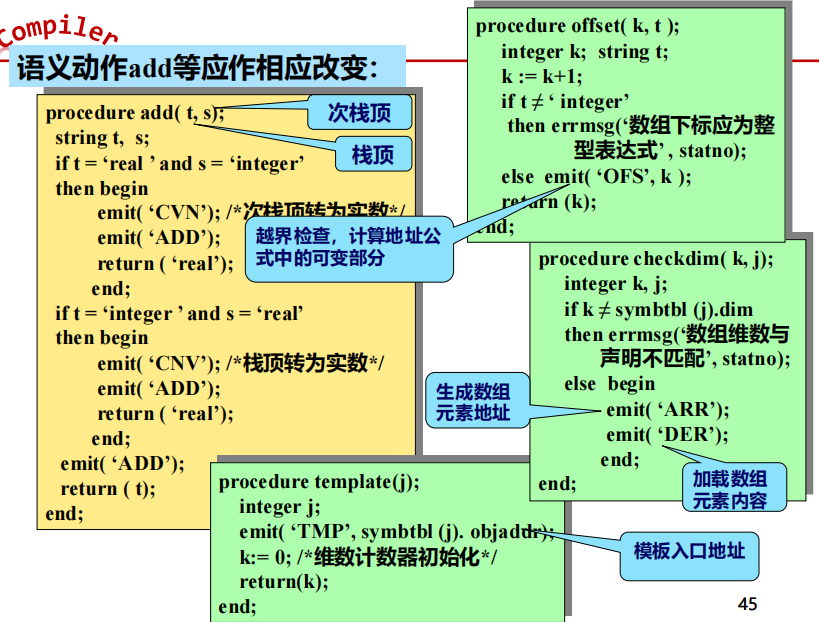

例:逻辑表达式

5 赋值语句的处理
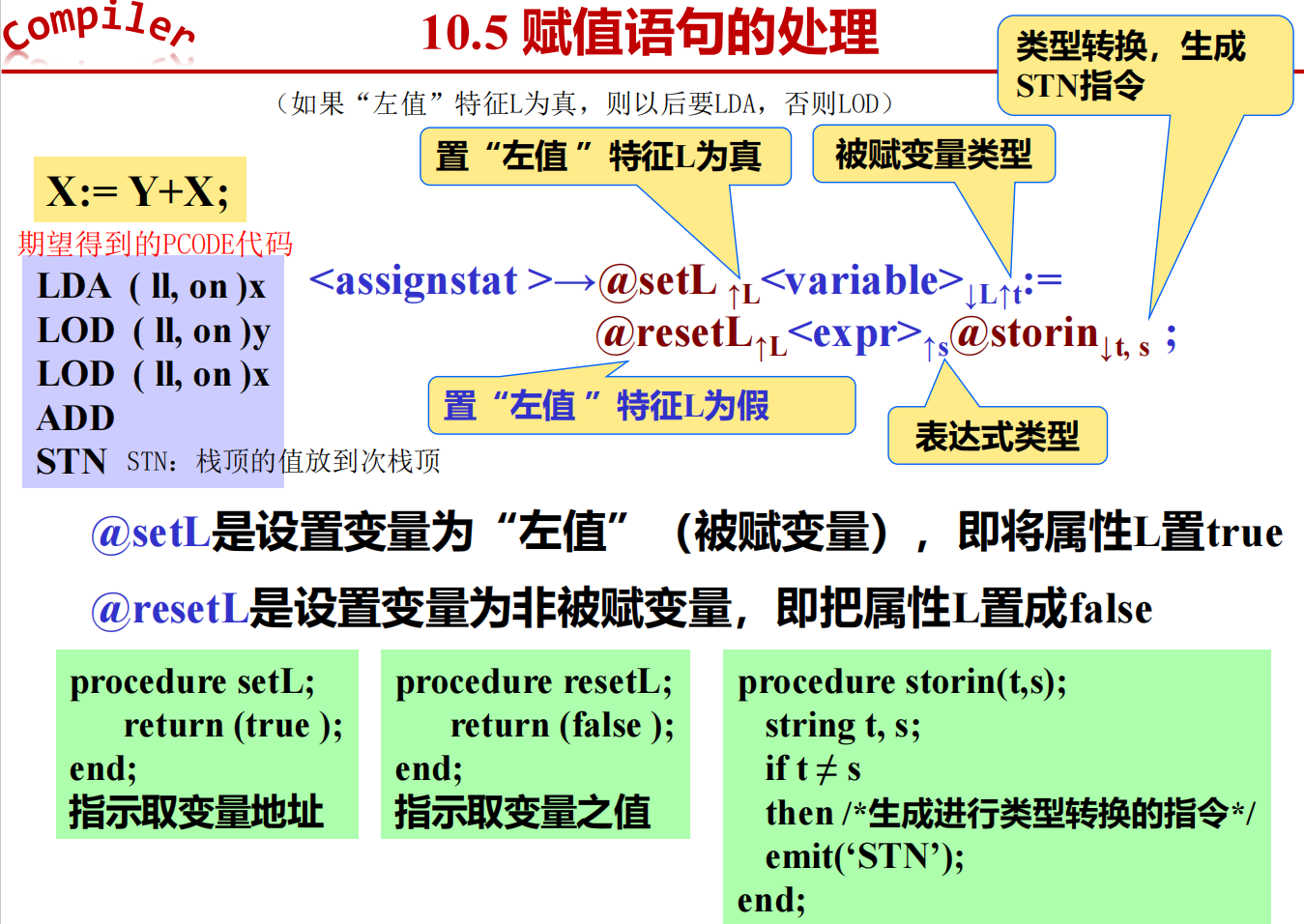
6 控制语句的处理
6.1 if 语句


6.2 for 循环

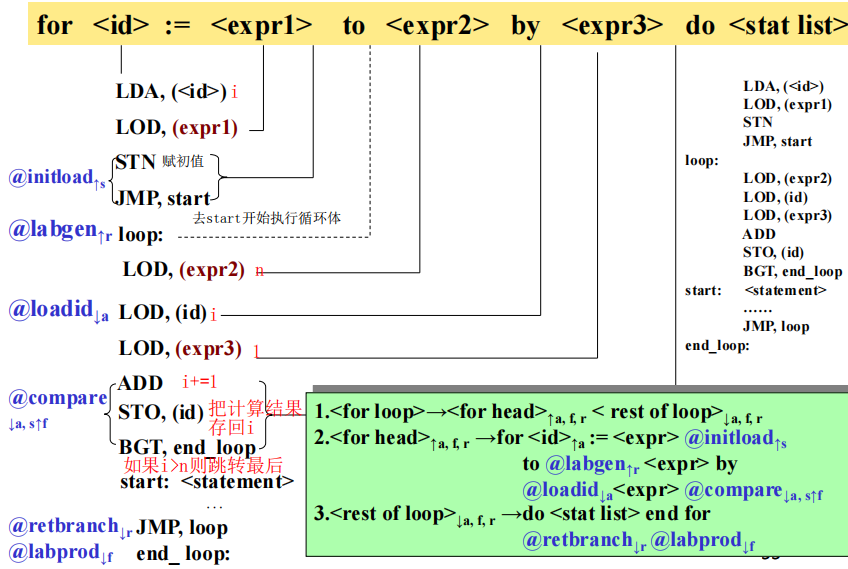

7 过程调用和返回
- 过程:无返回值
- 函数:有/无返回值
(此处的过程调用和返回既包括过程也包括函数)
7.1 参数传递的基本形式

7.1.1 传值(call by value)——值调用
- 实现:
调用段(过程语句的目标程序段):计算实参值 => 操作数栈栈顶
被调用段(过程说明的目标程序段):从栈顶取得值 => 形参单元 - 过程体中对形参的处理:对形参的访问等于对相应实参的访问
- 特点:数据传递是单向的
- 如C语言,Ada语言的in参数,Pascal 的值参数。
7.1.2 传地址(call by reference)——引用调用
- 实现:
调用段:计算实参地址 => 操作数栈栈顶
被调用段:从栈顶取得地址 => 形参单元 - 过程体中对形参的处理:通过对形参的间接访问来访问相应的实参
- 特点:结果随时送回调用段
- 如:FORTRAN,Pascal 的变量形参。
7.1.3 传名(call by name)
- 又称“名字调用”。即把实参名字传给形参。这样在过程体中引用形参时,都相当于对当时实参变量的引用。
- 当实参变量为下标变量时,传名和传地址调用的效果可能会完全不同。
- 传名参数传递方式,实现比较复杂,其目标程序运行效率较低, 现已很少采用。
- 如:ALGOL 的换名形参。
7.2 过程调用处理
1 调用
与调用有关的动作如下 :
- 检查该过程名是否已定义(过程名和函数名不能用错),实参和形参在类型、顺序、个数上是否一致。(查符号表)
- 加载实参(值或地址)(放到操作数栈顶)
- 加载返回地址(放到操作数栈顶)
- 转入过程体入口地址
process_symb(symb, cursor,replacestr);调用该过程生成的目标代码为:
LOD, (addr of symb )
LOD, (addr of cursor )
LOD, (addr of replacestr)
JSR, ( addr of process_symb)
<retaddr>:….
- 若实参并非上例中所示变量,而是表达式,则应生成相应计算实参表达式值的指令序列。
JSR指令先把返回地址压入操作数栈,然后转到被调过程入口地址。
2 声明
- 过程调用时,实参加载指令是把实参变量内容(或地址)送入操作数栈顶,过程声明处理时,应先生成把操作数栈顶的实参送运行栈AR中形参单元的指令。
- 将操作数栈顶单元内容存入运行栈(动态存储分配的数据区)当前活动记录的形式参数单元。
- 可认为此时运行栈和操作数栈不是一个栈(分两个栈处理)
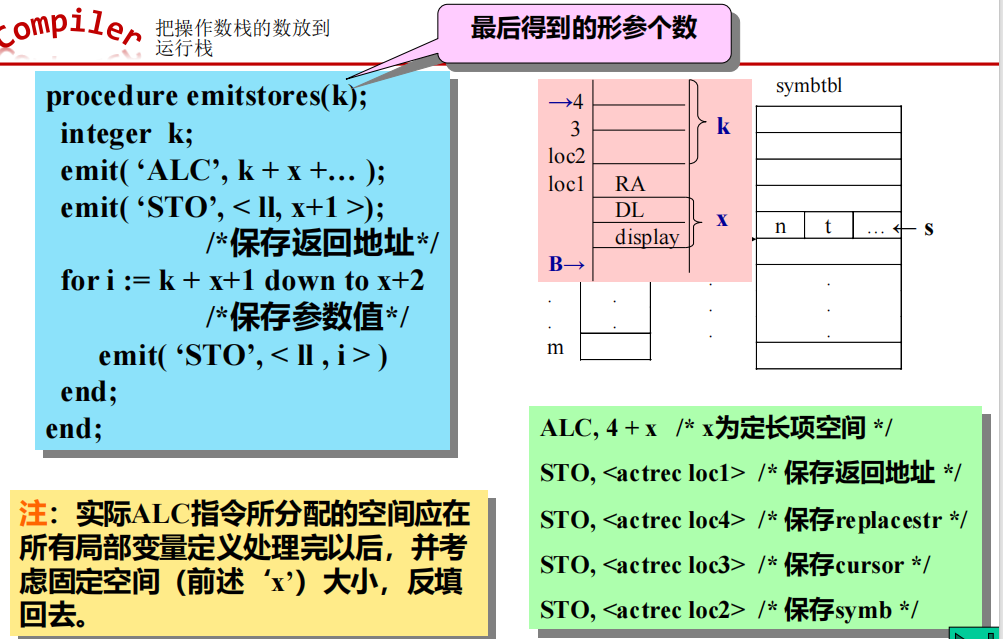
procedure process_symb(string:symbal, int: cur, string: repl);则过程体目标代码的开始处应生成以下指令,以存储返回地址和形参的值。
ALC, 4 + x /* x为定长项空间 display 和 DL */
STO, <actrec loc1> /* 保存返回地址 */
STO, <actrec loc4> /* 保存replacestr */
STO, <actrec loc3> /* 保存cursor */
STO, <actrec loc2> /* 保存symb */
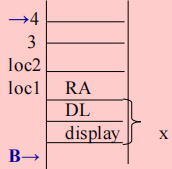
3 过程调用的ATG文法


4 过程声明的 ATG 文法
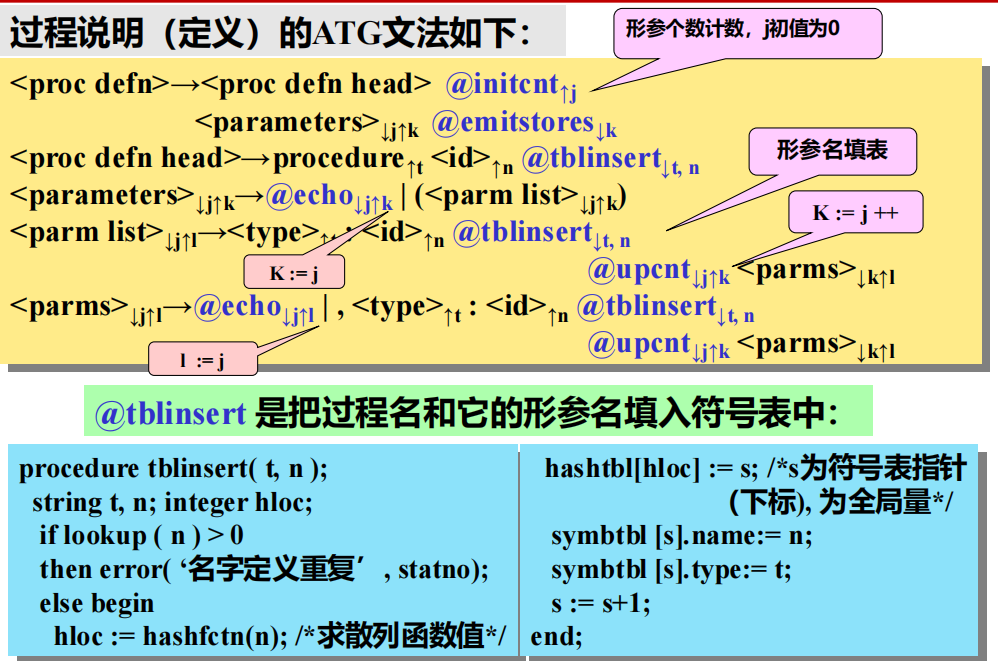
7.3 返回语句和过程体结束的处理
其语义动作有:
- 若为函数过程,应将操作数栈(或运行栈)顶的函数结果值送入(存回)函数值结果单元
- 生成无条件转移返回地址的指令(JMP RA)
- 产生删除运行栈中被调用过程活动记录的指令(只要根据DL—活动链,把abp退回去即可)
